Najnowsza aktualizacja Cursor, znana jako „Cursor 3.3”, wprowadza istotne zmiany w środowisku programistycznym. Program nie tylko wspiera pisanie kodu, ale staje się centralnym punktem w cyklu życia oprogramowania. Użytkownicy zyskają wbudowany workflow do obsługi pull requestów oraz możliwość równoległego uruchamiania niezależnych zadań przez agentów. Usprawnienia są dostępne w ramach stopniowo wdrażanej aktualizacji i nie wymagają skomplikowanej konfiguracji – wiele z nich działa od razu po włączeniu nowej wersji edytora.
Kluczowe nowości w najnowszym wydaniu
- Obsługa PR-ów bez opuszczania Cursor – tworzenie, przeglądanie i scalanie pull requestów w jednym oknie.
- Równoległe wykonywanie planów – Cursor identyfikuje niezależne części planu i uruchamia je jednocześnie przez asynchroniczne podagenty, zachowując kolejność tam, gdzie występują zależności.
Przegląd PR bez opuszczania edytora
Dla wielu programistów przeglądanie pull requestów wiąże się z ciągłym przełączaniem się między IDE a przeglądarką, co wymaga śledzenia wątków recenzji, komentarzy, historii commitów i drzewa plików w różnych zakładkach. Nowa wersja Cursor 3.3 eliminuje tę konieczność – okno agenta zyskało przestrzeń do zarządzania PR-ami. Użytkownicy mogą tworzyć, recenzować i scalać zgłoszenia bez odchodzenia od edytora. Dzięki temu kontekst kodu pozostaje nienaruszony, a programista nie musi przypominać sobie stanu projektu po powrocie z zewnętrznego narzędzia.
Zespół rozwija ideę „end-to-end coding”, gdzie etapy pracy nad oprogramowaniem są coraz bardziej zintegrowane w jednym środowisku.
Równoległe uruchamianie zadań
Kolejną istotną zmianą jest możliwość równoczesnego wykonywania niezależnych części planu. Zamiast czekać na przetworzenie jednego zadania po drugim, użytkownicy mogą teraz zlecić Cursorowi identyfikację fragmentów, które nie są ze sobą powiązane, i ich równoległe uruchomienie. Edytor wykorzystuje asynchroniczne podagenty, operujące na izolowanych git worktrees. Jeśli jakieś kroki muszą być wykonane sekwencyjnie (np. kompilacja przed testami), Cursor zachowa odpowiednią kolejność.
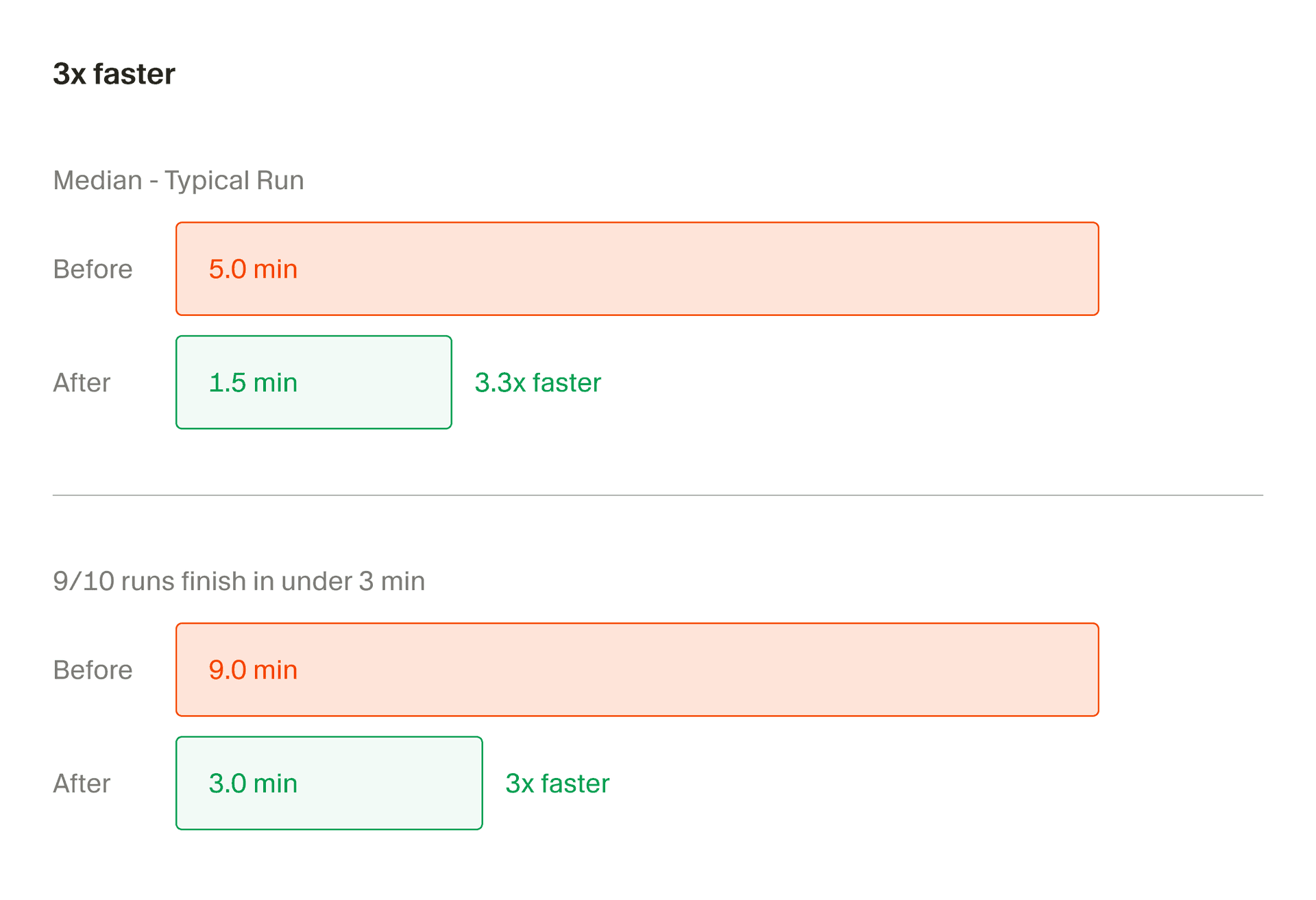
To oznacza znaczące skrócenie czasu oczekiwania na wyniki. Deweloperzy korzystający z intensywnego generowania kodu przez AI mogą teraz zlecać wiele współbieżnych zadań i obserwować ich postęp w jednym oknie. Jak podają twórcy, wystarczy kliknąć „Build in Parallel”, aby zidentyfikować niezależne części planu i uruchomić je jednocześnie, zachowując kolejność kroków, które muszą być wykonane w odpowiedniej sekwencji.
Inne usprawnienia
Oprócz głównych nowości, Cursor 3.3 wprowadza również szereg mniejszych zmian, takich jak Design Mode oraz udoskonalenia w pracy z przeglądarką. To pokazuje, że edytor rozwija się w różnych kierunkach – od interfejsu użytkownika po backendowe mechanizmy współbieżności.
Co to oznacza dla codziennej pracy programisty?
Kumulacja tych nowości ma na celu zacieśnienie integracji edytora z całym cyklem wytwarzania oprogramowania. Obsługa PR-ów w tym samym oknie eliminuje konieczność przełączania kontekstu i utrzymuje ciągłość myślenia. Równoległe uruchamianie zadań lepiej wykorzystuje moc obliczeniową i skraca czas oczekiwania. Dla zespołów webowych, które coraz częściej sięgają po AI, Cursor oferuje płynniejszy przepływ od pomysłu do wdrożenia, zachowując kontrolę programisty na każdym etapie.
Nowe funkcje są już dostępne w ramach aktualizacji i nie wymagają dodatkowej subskrypcji ani skomplikowanej konfiguracji – wystarczy uruchomić najnowszą wersję Cursor. W obliczu rosnącej złożoności projektów i presji na szybkie dostarczanie oprogramowania, takie narzędzia stają się nieodzownym elementem nowoczesnego warsztatu.