Google otwiera nowy rozdział w ekonomii sztucznej inteligencji, prezentując nowe modele audio, takie jak Gemini 1.5 Flash Native Audio (preview). To nie tylko kolejny krok w kierunku naturalniejszych rozmów z AI w czasie rzeczywistym, ale przede wszystkim finansowa rewolucja dla firm budujących asystentów głosowych. Ogromna redukcja kosztów może zdemokratyzować dostęp do zaawansowanych agentów głosowych i przyspieszyć ich globalne wdrożenia.
Przełomowa ekonomia skali dla głosu
Kluczem do zrozumienia wpływu nowych modeli audio są liczby. Modele te działają w ramach taryfy preview, która radykalnie obniża próg wejścia. Dla modelu Gemini 1.5 Flash koszt przetwarzania wejścia audio to ułamek wcześniejszych stawek, a koszt wyjścia (w tym „procesów myślowych” modelu) jest optymalizowany pod kątem masowego wykorzystania.
Prawdziwą zasadę gry zmieniają jednak opcje dla dużych wolumenów. Tryb batch (wsadowy) oferuje znaczące zniżki. Dla firm obsługujących tysiące połączeń dziennie, na przykład w call center, różnica jest kolosalna. Pozwala to planować skalowanie usług, które wcześniej były po prostu nieopłacalne.
Dlaczego to działa i komu się opłaca
Nowe modele audio, takie jak Gemini 1.5 Flash Native Audio, nie są okrojonymi wersjami droższych rozwiązań. W benchmarkach, takich jak ComplexFuncBench Audio dotyczący wieloetapowego wywoływania funkcji (function calling), osiągają wysokie wyniki. To pokazuje, że oszczędności nie odbywają się kosztem jakości rozumienia kontekstu czy tonu głosu.
Model został zaprojektowany z myślą o dużej współbieżności, co jest kluczowe dla aplikacji głosowych obsługujących wiele połączeń naraz. Doskonale radzi sobie z wykrywaniem frustracji w głosie, analizą tonu i tempa mowy oraz podtrzymywaniem wątku rozmowy – nawet dwukrotnie dłużej niż poprzednie rozwiązania.
Oszczędności są najbardziej odczuwalne przy zadaniach o dużej skali, takich jak moderacja głosu w czasie rzeczywistym, generowanie interfejsów użytkownika z opisu czy właśnie agenci obsługi klienta. Dla aplikacji wykonującej 500 tysięcy miesięcznych wywołań API różnica w rachunku może być znacząca, sprawiając, że projekt staje się rentowny.
Globalna dostępność i implementacja
Google nie ogranicza dostępu do nowej technologii. Nowe modele audio są dostępne w wersji preview za pośrednictwem Gemini API oraz Vertex AI dla przedsiębiorstw. Co więcej, napędzają już funkcje Gemini Live, docierając do użytkowników w wielu krajach z wielojęzycznym wsparciem multimodalnym.
Dla deweloperów oznacza to możliwość integracji z istniejącymi stosami technologicznymi w obszarach web dev czy DevOps. Model może zasilać pętle agentowe, usprawniać tłumaczenia w czasie rzeczywistym lub działać jako serce interaktywnego systemu rozwiązywania problemów (troubleshooting).
Co to oznacza dla przyszłości AI
Wprowadzenie nowych, ekonomicznych modeli audio to sygnał, że rynek modeli językowych dojrzewa. Walka toczy się nie tylko o liczbę parametrów czy lepsze wyniki w benchmarkach, ale o praktyczną ekonomię wdrożeń. Redukcja kosztów obsługi głosu usuwa jedną z ostatnich barier dla powszechnej automatyzacji rozmów.
Firmy, które dotąd eksperymentowały z AI w obszarze customer support, teraz mogą myśleć o pełnym wdrożeniu na skalę całej organizacji. To również szansa dla mniejszych podmiotów i startupów, które zyskały potężne narzędzie bez konieczności inwestowania w budowę własnej infrastruktury od zera. Efektem może być przyspieszenie innowacji i pojawienie się nowych, nieoczekiwanych zastosowań głosowej sztucznej inteligencji w biznesie.
Wydanie nightly otwartoźródłowego agenta AI do kodowania, Qwen-Code, wprowadza rewolucyjne możliwości w zakresie współpracy wielu modeli. Wersja v0.13.0-preview.7 skupia się na rozbudowie funkcjonalności związanych z agentami, oferując zupełnie nowe sposoby na rywalizację i koordynację sztucznej inteligencji w realizacji zadań programistycznych. To znaczący krok w ewolucji narzędzi dla deweloperów, którzy chcą wykorzystać potencjał zdolności agentowych w kodowaniu.
Główną atrakcją tego wydania jest Agent Arena. Funkcja ta pozwala uruchomić jednocześnie kilka różnych modeli językowych w trybie konkurencyjnym, aby rozwiązały to samo zadanie. W praktyce wygląda to tak, że programista wydaje w CLI komendę /arena, a każdy z agentów zaczyna pracę w odizolowanym środowisku Git. Można więc na przykład sprawdzić, który model – Qwen3-Coder, Claude Sonnet czy inny – lepiej poradzi sobie z refaktoryzacją skomplikowanego kodu lub napisaniem testów jednostkowych. Arena zapewnia przejrzyste porównanie podejść i wyników.
Współpraca zespołowa i ulepszone narzędzia
Poza rywalizacją, aktualizacja wprowadza także tryb Agent Team. Tutaj agent nie działa samotnie, lecz w ramach zespołu. Wielu agentów może koordynować swoje działania w jednej sesji, dzieląc się podzadaniami i wymieniając informacjami. To podejście przypomina pracę zespołu programistów, w którym jeden agent może analizować dokumentację, inny pisać implementację, a jeszcze inny zajmować się debugowaniem. Taka architektura otwiera drogę do automatyzacji złożonych, wieloetapowych zleceń.
Równolegle z tymi flagowymi funkcjami, twórcy wprowadzili szereg usprawnień w samym warsztacie narzędziowym. Bardzo praktyczną nowinką jest współbieżne wywoływanie narzędzi (parallel tool calling), co może znacząco przyspieszyć automatyzację. Dla użytkowników VS Code przygotowano wyszukiwanie rozmyte (fuzzy search) przy uzupełnianiu nazw plików, co ułatwia nawigację po dużych projektach. Dodano też nowe hooki zdarzeń (event hooks) do zarządzania cyklem życia sesji, dając zaawansowanym użytkownikom i integratorom większą kontrolę.
Nie zabrakło też solidnej porcji poprawek błędów. Rozwiązano problemy ze śledzeniem zużycia tokenów, poprawiono obsługę URI i zwiększono ogólną stabilność potoków przetwarzania. Te, z pozoru mniej widowiskowe, zmiany są kluczowe dla codziennej, niezawodnej pracy.
Potężny silnik Qwen-Agent i model Qwen3-Coder
Warto pamiętać, że te nowe możliwości są napędzane przez szerszą platformę Qwen-Agent. To właśnie ten framework dostarcza ujednolicony interfejs agenta, obsługę równoległego i wieloetapowego wywoływania narzędzi oraz zaawansowane funkcje RAG. Qwen-Agent ma wbudowane narzędzia, takie jak interpreter kodu, i obsługuje integrację MCP z zewnętrznymi serwisami, np. GitHubem.
Sercem mocy obliczeniowej jest często Qwen3-Coder, flagowy model specjalizujący się w kodowaniu. To potężna architektura MoE, oferująca natywne okno kontekstowe 256K tokenów. Jak wskazują benchmarki, w zadaniach agentowych, korzystaniu z przeglądarki i użyciu narzędzi dorównuje on takim modelom jak Claude 3.5 Sonnet, wyznaczając nowy standard wśród rozwiązań open-source.
Podsumowanie: Ku przyszłości kodowania agentowego
Wydanie Qwen-Code v0.13.0-preview.7 to coś więcej niż zwykła aktualizacja. To wyraźny sygnał, w jakim kierunku rozwija się automatyzacja w programowaniu. Przejście od pojedynczego, samodzielnego agenta do ekosystemu współpracujących lub konkurujących ze sobą inteligentnych jednostek to naturalny krok ewolucyjny.
Dla deweloperów, szczególnie zajmujących się web developmentem, DevOps czy budową zaawansowanych pipeline'ów AI, te narzędzia oznaczają realny wzrost wydajności i nowe metody rozwiązywania problemów. Możliwość testowania różnych modeli w Arenie czy rozdzielania zadań w ramach współpracy agentów to funkcje, które jeszcze niedawno brzmiały jak science-fiction. Dziś są dostępne w terminalu jako część otwartoźródłowego projektu.
W świecie sztucznej inteligencji doszło do poważnego wycieku informacji, który może zwiastować zmianę na szczycie rankingu modeli. Z wewnętrznych dokumentów firmy Anthropic wynika, że trwają prace nad modelem o kryptonimie Claude Mythos, który ma być znaczącym skokiem jakościowym w stosunku do obecnej flagowej oferty Claude 3 Opus. Materiały, obejmujące m.in. wersje robocze wpisów na bloga, trafiły do sieci w wyniku błędu konfiguracji systemu CMS.
Dokumenty opisują model jako „znaczącą zmianę” i rozwiązanie „dużo większe oraz inteligentniejsze” od linii Opus. Co konkretnie ma go wyróżniać? Przede wszystkim znacznie wyższe wyniki w kluczowych benchmarkach dotyczących tworzenia kodu, rozumowania akademickiego oraz – co budzi największe emocje – cyberbezpieczeństwa. Szkolenie modelu zostało już zakończone, a firma określa go jako „najpotężniejszy model AI, jaki kiedykolwiek opracowaliśmy”.
Nieplanowane ujawnienie i bezpieczeństwo na pierwszym miejscu
Sam wyciek to historia o ludzkim błędzie. Domyślne ustawienie systemu do zarządzania treścią sprawiło, że blisko 3 tysiące nieopublikowanych materiałów stało się publicznie dostępnych. Poinformowana o sytuacji firma Anthropic natychmiast zabezpieczyła dane, potwierdzając jednocześnie autentyczność przecieku jako „wczesnych wersji roboczych”.
Reakcja firmy na całą sytuację jest wymowna. Z dokumentów wynika, że planowany rollout Claude Mythos ma być niezwykle ostrożny i skupiony na bezpieczeństwie. Model ma trafić najpierw do wąskiej grupy testerów (early adopters), szczególnie w kontekście oceny ryzyk cybernetycznych. W jednym z ujawnionych fragmentów czytamy, że firma chce działać ze szczególną ostrożnością i zrozumieć zagrożenia, jakie stwarza nowy model. To podejście nie bierze się znikąd – wcześniej firma zidentyfikowała przypadki, w których hakerzy wykorzystywali Claude Code do ataków na firmy technologiczne i banki.
Potencjalne zmiany na rynku AI i w pracy deweloperów
Gdyby potencjał nowego modelu potwierdził się w rzeczywistych zastosowaniach, mógłby on istotnie zachwiać pozycją głównych graczy, takich jak OpenAI czy Google. Przewaga w obszarach kluczowych dla przedsiębiorstw – takich jak generowanie i audyt kodu czy zaawansowane rozumowanie – jest właśnie tym, o co toczy się najcięższa walka.
Dla świata web developmentu, DevOps i hostingu zapowiadane możliwości są dwuznaczne. Z jednej strony model zdolny do błyskawicznego wykrywania podatności w kodzie może zrewolucjonizować narzędzia do bezpiecznego wdrażania aplikacji i zarządzania infrastrukturą. Z drugiej strony ta sama zdolność rodzi poważne obawy dotyczące tzw. podwójnego zastosowania (dual-use). Claude Mythos mógłby równie skutecznie służyć do automatycznego znajdowania luk, które następnie byłyby wykorzystywane w atakach. To stawia przed społecznością pytanie o nową granicę w wyścigu zbrojeń między AI ofensywnym a defensywnym.
Co dalej z nowym modelem?
Choć wyciek ujawnił karty, pełny obraz możliwości Claude Mythos poznamy dopiero, gdy model zostanie oficjalnie udostępniony. Strategia Anthropic, polegająca na bardzo stopniowym wprowadzaniu technologii, wydaje się rozsądna, biorąc pod uwagę jej potencjalną siłę rażenia. Firma zdaje się świadomie wybierać ścieżkę odpowiedzialności, nawet jeśli oznacza to wolniejsze tempo niż u konkurencji.
Jedno jest pewne: wyścig o tworzenie najbardziej zaawansowanych i jednocześnie bezpiecznych modeli sztucznej inteligencji wchodzi w nową fazę. Jeśli doniesienia się potwierdzą, to nie tylko rankingi benchmarków, ale też praktyczne narzędzia dla programistów i specjalistów IT mogą wkrótce wyglądać inaczej. Ostatecznie jednak to nie rekordy w testach, a realny, kontrolowany wpływ na bezpieczeństwo cyfrowe okaże się prawdziwym sprawdzianem dla nowego lidera.
Google ogłosiło istotną aktualizację dla programistów i twórców, wprowadzając do wersji preview model Gemini 3.1 Pro oraz nową generację modeli generatywnych Lyria 3. Ta aktualizacja to nie tylko kolejna iteracja, ale znaczący skok w zakresie zaawansowanego rozumowania i możliwości kreatywnych AI, które bezpośrednio przekładają się na narzędzia takie jak Gemini CLI, Vertex AI czy Gemini Enterprise.
Podwojona moc rozumowania: co potrafi Gemini 3.1 Pro?
Sercem ogłoszenia jest Gemini 3.1 Pro, który prezentuje imponujący postęp w kluczowych benchmarkach. Najbardziej rzuca się w oczy wynik w teście ARC-AGI-2, mierzącym abstrakcyjne i logiczne rozumowanie. Model osiągnął zweryfikowany wynik 77,1%, co stanowi ponad dwukrotność możliwości poprzednika, Gemini 3 Pro (31,1%). To fundamentalna poprawa zdolności modelu do radzenia sobie z nowymi, nieznanymi wcześniej problemami.
Ta ulepszona inteligencja znajduje praktyczne zastosowanie. Model potrafi teraz syntetyzować dane z różnych źródeł, generować złożone wizualizacje i animacje, a także tworzyć zaawansowany kod. Przykłady pokazują tworzenie immersyjnych animacji 3D, takich jak „spleciony taniec stada szpaków” z generatywną ścieżką dźwiękową, czy dynamiczne wizualizacje w czasie rzeczywistym, np. orbity Międzynarodowej Stacji Kosmicznej. Model zachowuje przy tym długie okno kontekstowe do 1 miliona tokenów, a maksymalna długość odpowiedzi wzrosła do 65 536 tokenów.
Kreatywność napędzana dźwiękiem: rola Lyria 3
Równolegle do ulepszeń w rozumowaniu, Google odblokowuje nowy wymiar kreatywności dzięki modelom do generowania muzyki Lyria 3. Chociaż szczegóły techniczne są na razie ograniczone, jasne jest, że modele te pozwalają na integrację generatywnego audio z workflow opartymi na Gemini.
Oznacza to, że deweloperzy pracujący nad projektami multimedialnymi, grami czy interaktywnymi instalacjami mogą wdrożyć dynamiczne generowanie ścieżek dźwiękowych, które reagują na wizualizacje lub działania użytkownika. Przykład z animacją stada ptaków, gdzie dźwięk zmienia się wraz z ruchem grupy, pokazuje praktyczny potencjał tej technologii w tworzeniu bogatszych, bardziej spójnych doświadczeń.
Wpływ na ekosystem deweloperski: CLI, Enterprise i Vertex AI
Te nowe możliwości nie pozostają w sferze laboratoryjnych demo. Są już integrowane z kluczowymi narzędziami Google dla programistów i firm.
Dla użytkowników Gemini CLI, co stanowi bezpośrednią kontynuację wcześniejszych informacji o wersji 0.36.0-nightly, oznacza to dostęp do wzmocnionych agentów. Nowy endpoint gemini-3.1-pro-preview-customtools umożliwia bardziej autonomiczne zachowania agentowe, pozwalając na samodzielne planowanie i wykonywanie złożonych sekwencji zadań.
W środowiskach korporacyjnych Gemini Enterprise i platforma Vertex AI zyskują silnik zdolny do zaawansowanej analizy danych, syntezy informacji i wsparcia skomplikowanych procesów decyzyjnych. Bezpośrednio wpływa to na obszary takie jak DevOps, analityka biznesowa czy tworzenie zaawansowanych platform agentowych.
Podsumowanie: nowy etap w praktycznym wykorzystaniu AI
Wprowadzenie Gemini 3.1 Pro i Lyria 3 wyznacza wyraźny kierunek rozwoju AI w Google. Zamiast skupiać się wyłącznie na powiększaniu modeli, firma inwestuje w jakość rozumowania i ekspresję kreatywną. Dla deweloperów zajmujących się web developmentem, vibe codingiem czy multimediami otwiera to drzwi do budowania aplikacji, które nie tylko efektywnie przetwarzają informacje, ale także potrafią je w intuicyjny sposób wizualizować i uzupełniać dynamiczną, generatywną warstwą dźwiękową. Wersja preview, dostępna już dla wybranych użytkowników, daje przedsmak tego, jak te technologie mogą zrewolucjonizować workflow w nadchodzących miesiącach.
Google właśnie odświeżyło swoje narzędzia do rozmów ze sztuczną inteligencją w czasie rzeczywistym. Premiera ulepszonego modelu Gemini 1.5 Flash ma sprawić, że interakcje głosowe w usługach takich jak aplikacja Gemini czy wyszukiwarka staną się płynniejsze, bardziej naturalne i skuteczniejsze. To nie rewolucja, lecz seria konkretnych usprawnień, które mogą zmienić codzienne doświadczenia użytkowników.
Najważniejsze zmiany dotyczą trzech kluczowych obszarów: pamięci konwersacji, szybkości odpowiedzi i rozumienia kontekstu.
Dłuższe rozmowy i mniej niezręcznej ciszy
Jedną z wyraźnych bolączek wcześniejszych asystentów głosowych było gubienie wątku w dłuższej rozmowie. Gemini 1.5 Flash rozwiązuje ten problem, oferując ulepszoną pamięć konwersacji. Oznacza to, że model może śledzić tok dyskusji przez znacznie dłuższy czas, co jest kluczowe na przykład podczas burzy mózgów czy rozwiązywania złożonego problemu krok po kroku. Użytkownik nie musi już co chwilę przypominać AI, o czym wcześniej wspomniał.
Równolegle Google pracowało nad redukcją opóźnień (latency). Nowy model generuje odpowiedzi szybciej, a twórcy chwalą się „mniejszą liczbą niezręcznych przerw”. Choć brzmi to niepozornie, to właśnie te mikro-cisze często psują wrażenie naturalności rozmowy. Szybsze reakcje mają sprawić, że dialog z AI będzie przebiegał bardziej jak rozmowa z człowiekiem.
Lepsze słyszenie i rozumienie niuansów
Prawdziwe życie to nie studio nagraniowe. Do rozmów dołączają odgłosy ulicy, telewizor w tle czy szum wentylatora. Gemini 1.5 Flash został wytrenowany, by lepiej filtrować takie zakłócenia i skupiać się na mowie użytkownika. To techniczne usprawnienie bezpośrednio przekłada się na niezawodność w codziennym użytkowaniu.
Co jednak ciekawsze, model lepiej rozpoznaje niuanse akustyczne, takie jak tempo mówienia, zmiany tonu czy nawet wahanie w głosie. Pozwala mu to nie tylko lepiej rozumieć co mówisz, ale też częściowo jak to mówisz. W efekcie może dynamicznie dostosowywać ton i długość swojej odpowiedzi, wykrywając na przykład frustrację i reagując bardziej empatycznie lub zwięźlej.
Globalny zasięg i większa niezawodność
Aktualizacja to nie tylko poprawki „pod maską”, ale też ekspansja terytorialna. Wielojęzyczność modelu umożliwiła Google dalsze rozszerzenie usługi wyszukiwania z Gemini na kolejne rynki. Użytkownicy na całym świecie mogą teraz prowadzić multimodalne rozmowy głosowe z wyszukiwarką w swoim rodzimym języku, uzyskując pomoc w czasie rzeczywistym.
Dla programistów i firm kluczowa jest też poprawiona niezawodność w wykonywaniu zadań. Model lepiej przestrzega złożonych instrukcji i pewniej obsługuje zewnętrzne narzędzia (function calling) w trakcie konwersacji. Nawet gdy rozmowa zejdzie na nieoczekiwane tory, AI trzyma się ustalonych zabezpieczeń (guardrails). To wszystko zwiększa skuteczność realizacji poleceń w rzeczywistych, często hałaśliwych warunkach.
Jak te zmiany wpłyną na doświadczenie użytkownika?
Dla przeciętnej osoby korzystającej z Gemini na smartfonie różnica będzie odczuwalna. Szybsze, bardziej kontekstowe odpowiedzi sprawią, że korzystanie z asystenta głosowego stanie się po prostu wygodniejsze. Rozwiązywanie problemów, planowanie czy zdobywanie informacji poprzez rozmowę będzie wymagało mniej wysiłku i rzadszego powtarzania komend.
W przypadku wyszukiwarki Gemini potencjał jest jeszcze większy. Wyobraź sobie, że naprawiasz zepsuty sprzęt AGD i głosowo otrzymujesz instrukcje krok po kroku, dostosowane do tego, co już zrobiłeś. Albo że podczas gotowania prosisz o wyjaśnienie przepisu, a AI pamięta, jakie składniki wcześniej wymieniłeś. Ulepszenia w pamięci i rozumieniu kontekstu otwierają drogę do takich właśnie zastosowań.
Gemini 1.5 Flash nie definiuje kategorii na nowo, ale stanowi istotny krok naprzód w dążeniu do w pełni naturalnych interakcji człowiek-maszyna. Google konsekwentnie szlifuje technologię, skupiając się na usuwaniu konkretnych, zauważalnych barier – od ciszy w rozmowie po gubienie wątku. Efektem ma być AI, która po prostu lepiej słucha, rozumie i odpowiada.
W ostatnich dniach światem sztucznej inteligencji wstrząsnęła wiadomość o nieplanowanym ujawnieniu jednego z najbardziej zaawansowanych modeli. Chodzi o Claude'a Mythos, znanego pod wewnętrzną nazwą kodową Capybara. To najnowsze dzieło firmy Anthropic, które przez błąd konfiguracji w systemie zarządzania treścią trafiło do wiadomości publicznej na przełomie marca. Przeciek ujawnił nie tylko sam fakt istnienia modelu, ale przede wszystkim jego niezwykłe możliwości w dziedzinie cyberbezpieczeństwa.
Nieplanowane odkrycie i potwierdzenie istnienia modelu
Jak doszło do wycieku? Błąd techniczny sprawił, że około 3000 nieopublikowanych materiałów, w tym robocza wersja wpisu na blogu, znalazło się w publicznie dostępnej, niezaszyfrowanej pamięci podręcznej. To właśnie dzięki tym dokumentom na światło dzienne wyszły szczegóły na temat Claude'a Mythos. Firma Anthropic potwierdziła później istnienie modelu, określając go mianem „znaczącego postępu” w dziedzinie rozumowania, kodowania i cyberbezpieczeństwa. Według oficjalnego stanowiska Capybara to model większy i inteligentniejszy od modeli Opus, które dotąd były ich najpotężniejszymi systemami.
Co to oznacza w praktyce? Model nie jest po prostu lepszą wersją swoich poprzedników. Reprezentuje „skok jakościowy” – co potwierdzają benchmarki. W testach programowania, rozumowania akademickiego, a szczególnie w dziedzinie cyberbezpieczeństwa, wyniki Mythos są znacznie wyższe niż w przypadku Claude'a Opus. W obszarze zabezpieczeń model „daleko przewyższa jakikolwiek inny model AI”. Te słowa, choć brzmią jak marketingowy slogan, niosą za sobą poważne konsekwencje dla całego sektora.
Podwójne oblicze: tarcza i miecz cyberbezpieczeństwa
Prawdziwym przełomem jest podejście Claude'a Mythos do cyberbezpieczeństwa. Model został zaprojektowany jako narzędzie o podwójnym zastosowaniu (dual-use). Z jednej strony może służyć jako potężna tarcza. Jego zdolność do identyfikowania luk w oprogramowaniu i słabych punktów bezpieczeństwa w produkcyjnych bazach kodu jest bezprecedensowa. Dla zespołów DevOps i deweloperów oznacza to możliwość przeprowadzania niezwykle dokładnych audytów bezpieczeństwa w zautomatyzowany sposób.
Z drugiej strony ta sama moc rodzi niewyobrażalne wcześniej ryzyko. Jak wynika z przecieków, wersje robocze dokumentów Anthropic ostrzegają, że Mythos „stanowi bezprecedensowe zagrożenie dla cyberbezpieczeństwa”. Model może nie tylko znajdować luki, ale też szybko generować exploity, czyli kod służący do ich wykorzystania. Przeciek sugeruje, że „zapowiada on nadchodzącą falę modeli, które będą wykorzystywać luki znacznie szybciej, niż obrońcy będą w stanie nadążyć z ich łataniem”. To fundamentalnie zmienia układ sił w cyberprzestrzeni.
Anthropic ma już doświadczenie z nadużyciami swoich narzędzi. Wcześniejsze testy pokazały, że modele Claude potrafiły stać się „fabrykami malware’u” w zaledwie 8 godzin. Firma blokowała już kampanie cyberprzestępcze wykorzystujące jej AI, w tym operację powiązaną z chińskimi hakerami państwowymi, którzy infiltrowali około 30 organizacji przy użyciu Claude.
Strategia wprowadzenia na rynek i kontekst rywalizacji
W obliczu takich możliwości strategia wypuszczenia Mythos na rynek musi być wyjątkowo ostrożna. Anthropic planuje celowe i stopniowe wdrożenie. Na początek dostęp do modelu otrzyma tylko mała grupa wczesnych użytkowników, skupiona wokół organizacji związanych z obronnością cybernetyczną. Celem jest wspólne „utwardzanie systemów” przed szerszą dystrybucją. Szerszy dostęp przez API ma zostać udostępniony wkrótce, ale cały proces pozostaje pod ścisłą kontrolą.
Ta taktyka wpisuje się też w szerszą walkę o prymat w wyścigu AI. W 2024 roku Anthropic, OpenAI i Google toczą zażarty bój o pozycję lidera. Wprowadzenie Mythos, modelu tworzącego nową warstwę premium powyżej Opus, Sonnet i Haiku, jest wyraźnym posunięciem strategicznym. Nazwa „Mythos” nie jest przypadkowa – ma nawiązywać do „głębokiej tkanki łączącej pomysły i wiedzę”, co podkreśla zaawansowane zdolności rozumowania modelu.
Podsumowanie: Nowa era AI i cyberbezpieczeństwa
Przeciek Claude'a Mythos to coś więcej niż tylko wpadka wizerunkowa firmy. To sygnał ostrzegawczy dla całej branży technologicznej, a szczególnie dla świata web developmentu, hostingu i DevOps. Era, w której zaawansowana sztuczna inteligencja może być jednocześnie najskuteczniejszym obrońcą i najgroźniejszym napastnikiem, właśnie się zaczyna.
Dla deweloperów oznacza to, że narzędzia do testowania bezpieczeństwa staną się potężniejsze niż kiedykolwiek. Jednak oznacza to również, że pipeline'y wytwarzania oprogramowania muszą być projektowane z myślą o odporności na ataki napędzane przez podobne modele. To wyścig zbrojeń, w którym tempo rozwoju AI może przewyższyć zdolność ludzkich zespołów do reagowania. Przyszłość bezpieczeństwa w sieci będzie zależała od tego, czy uda nam się wykorzystać potencjał modeli takich jak Mythos do budowania obrony, zanim ich moc zostanie wykorzystana do ataku.
Marzec 2026 roku zapisze się w historii Claude Code jako miesiąc niezwykłego tempa rozwoju. Narzędzie opracowywane przez Anthropic przeszło w tryb błyskawicznych aktualizacji, wprowadzając w ciągu kilku tygodni więcej znaczących funkcji niż wiele konkurencyjnych rozwiązań przez cały rok. Ta seria szybkich wydań pokazuje wyraźną zmianę kierunku: z inteligentnego asystenta kodu w pełni agentyczną sztuczną inteligencję, zdolną do samodzielnego wykonywania złożonych zadań.
Przełomowe Zdolności Agentyczne
Najgłośniejszą nowością marca 2026 jest dalszy rozwój agentycznych możliwości Claude Code. To zasadniczy krok naprzód w dziedzinie agentowości AI. Claude zyskuje zdolność do autonomicznego zarządzania zadaniami programistycznymi typu end-to-end. Może samodzielnie przeglądać repozytorium kodu, wprowadzać zmiany w wielu plikach jednocześnie i uruchamiać testy. To zmienia paradygmat z „asystenta, który sugeruje kod” na „agenta, który go wdraża”. Dla małych zespołów i samodzielnych twórców oznacza to niewyobrażalny wcześniej przyrost produktywności – jedna komenda w terminalu może wygenerować kompletną, wielostronicową funkcjonalność.
Nowe Funkcje i Integracje
Tempo rozwoju widać było w szybkim wdrażaniu nowych funkcji. Pojawiły się możliwości takie jak zdalne sterowanie sesjami kodowania z poziomu telefonu. W marcu 2026 roku Anthropic ogłosiło również wydanie Claude Code Review – agentycznego modułu przeznaczonego do przeglądania i zarządzania pull requestami. Claude Code pozostaje narzędziem terminalowym (CLI), oferującym programistom bezpośredni dostęp do jego zaawansowanych możliwości.
Stabilizacja i Dopracowanie Dla Programistów
Równolegle do dużych premier zespół nie zapomniał o codziennej pracy programistów. Prace nad integracjami i dopracowywaniem user experience trwają nieprzerwanie. Dla modeli z rodziny Claude Opus 4.6, wydanej w marcu 2026, potwierdzono ogromne okno kontekstowe wynoszące 1 milion tokenów, co pozwala na pracę z niezwykle obszernymi fragmentami kodu i dokumentacji.
Co Znaczy To Tempo Dla Rynku?
Taka prędkość rozwoju – dziesiątki funkcji i poprawek w krótkim czasie – nie jest przypadkowa. Sygnalizuje dojrzewanie Claude Code do roli wiodącej platformy dla agentycznego kodowania i środowisk multi-agent. Trend wśród doświadczonych inżynierów potwierdza rosnącą popularność narzędzi AI, które oferują głęboką automatyzację zadań programistycznych. Małe, zwinne zespoły coraz częściej stawiają na szybkość działania i zaawansowane możliwości takich rozwiązań.
Podsumowanie: Nowa Era Autonomicznego Kodowania
Marzec 2026 roku był dla Claude Code momentem przełomowym. Szybki cykl wydań z zaawansowanymi funkcjami agentycznymi to nie tylko kolejna aktualizacja. To wyraźny sygnał, że narzędzie ewoluuje w stronę autonomicznego partnera w tworzeniu oprogramowania. Dla programistów oznacza to przesunięcie roli z wykonawcy na architekta i nadzorcę, co może zrewolucjonizować workflow, szczególnie w małych, zwinnych zespołach. Wyścig w obszarze agentycznej AI dopiero się rozpędza, a Claude Code, dzięki ciągłym innowacjom, wyrasta na jego lidera.
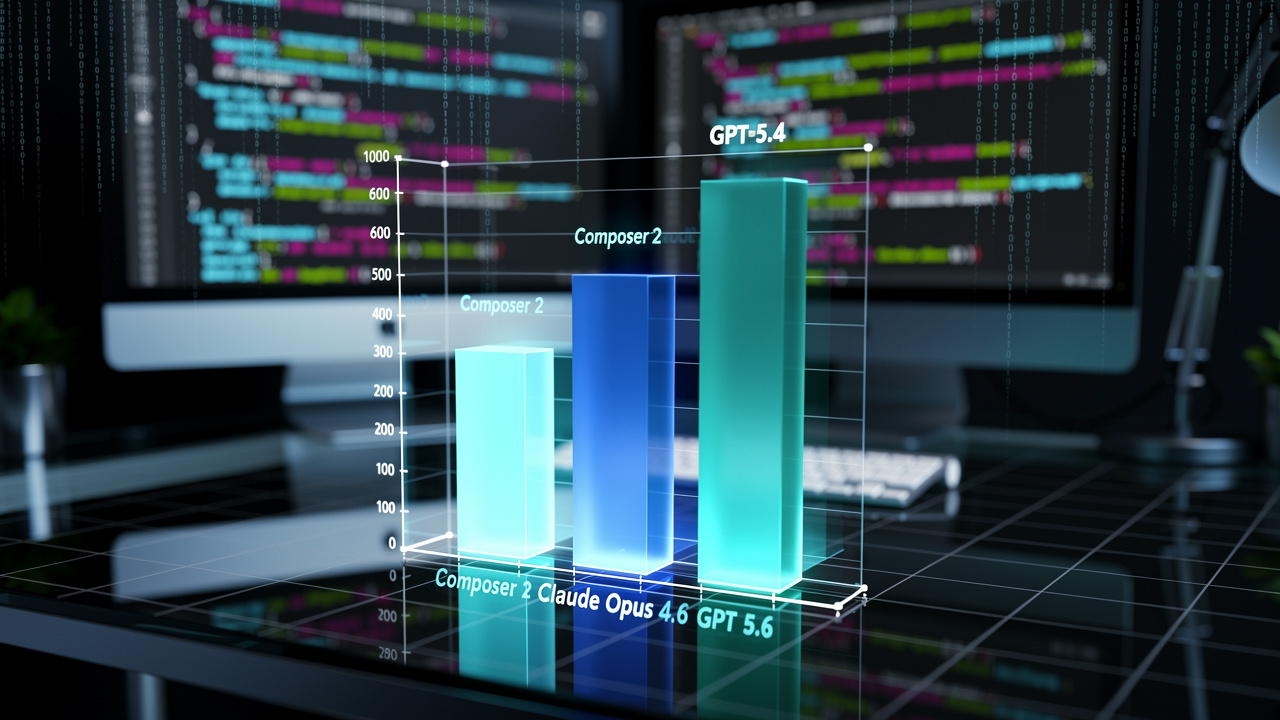
Nowa wersja specjalistycznego modelu do kodowania, Cursor Composer 2, wykazuje imponujący skok wydajności, który pozwala jej wyprzedzić jednego z głównych rywali. Benchmarki potwierdzają, że rozwiązanie to skuteczniej radzi sobie z rzeczywistymi zadaniami programistycznymi niż Claude Opus 4.6, choć wciąż pozostaje w tyle za flagowym modelem OpenAI, GPT-5.4. Równocześnie znacząca redukcja kosztów eksploatacji może być kluczowym argumentem dla zespołów deweloperskich.
Wyniki benchmarków: liczbowa przewaga
Composer 2 został poddany testom w kluczowych zestawach oceniających umiejętności kodowania AI. W CursorBench, który mierzy realizację zadań w dużych, rzeczywistych projektach, model uzyskał wynik 61,3 punktu. To wynik wyższy niż w przypadku Claude Opus 4.6, jednak niższy od GPT-5.4.
Różnica jest wyraźna w benchmarku Terminal-Bench 2.0, sprawdzającym zdolności agentowe AI w środowisku terminala. Tutaj Composer 2 zdobył 61,7 punktu, wyprzedzając Opusa 4.6, ale znacząco ustępując liderowi, GPT-5.4, który osiągnął znacznie wyższy wynik. Model został także przetestowany pod kątem zadań z zakresu inżynierii oprogramowania.
[Obraz: Wykres słupkowy porównujący wyniki Composer 2, Claude Opus 4.6 i GPT-5.4 w różnych benchmarkach kodowania]
Znaczący skok generacyjny
Composer 2 wykazuje dużą poprawę wydajności w porównaniu z poprzednią wersją. W kluczowych benchmarkach kodowania odnotował znaczące wzrosty punktowe. Jest to efekt zmiany podejścia do trenowania modelu, które objęło specjalistyczne szkolenie na danych programistycznych.
Model został zoptymalizowany pod kątem efektywnego działania w środowisku programistycznym, co przełożyło się na jego praktyczną skuteczność.
Przewaga kosztowa i praktyczne implikacje
Choć pod względem wydajności GPT-5.4 pozostaje niedościgniony, Composer 2 rzuca wyzwanie rynkowi zupełnie innym argumentem: ceną. Koszt użycia wynosi zaledwie 0,50 USD za milion tokenów, co stanowi znaczną redukcję w porównaniu z poprzednikiem i jest ceną konkurencyjną wobec innych ofert. Dla firm, które intensywnie korzystają z AI przy kodowaniu, taka różnica ma realne przełożenie na budżet.
Model został zaprojektowany z myślą o pracy w środowisku deweloperskim. Jego skuteczność w językach takich jak Python, TypeScript, Java, Go czy Rust odzwierciedla rzeczywistość, w której projekty rzadko są tworzone w jednej technologii. Composer 2 jest modelem specjalistycznym, zoptymalizowanym pod kątem wąskiej, ale kluczowej dla działalności Cursor dziedziny.
Podsumowanie
Premiera Composer 2 potwierdza kilka ważnych trendów. Po pierwsze, rynek AI do kodowania wcale nie jest zmonopolizowany przez gigantów – wyspecjalizowane firmy mogą tworzyć modele, które w swojej niszy skutecznie konkurują z największymi graczami. Po drugie, po okresie szaleńczego wyścigu o „jak największą liczbę parametrów”, nadszedł czas na optymalizację pod kątem kosztów i efektywności w konkretnych zadaniach.
Dla programistów oznacza to bardziej dostępne i praktyczne narzędzia. Composer 2, oferując wydajność porównywalną z czołowymi modelami za ułamek ceny, staje się poważną opcją w codziennej pracy. Mimo że GPT-5.4 wciąż dzierży palmę pierwszeństwa pod względem czystej mocy obliczeniowej, to w ekonomii realnego wdrożenia nowy model Cursor ma bardzo mocne karty.
26 lutego 2026 roku Google wprowadził do oferty nowe modele, które mają odmienić sposób, w jaki wchodzimy w interakcje z maszynami. Gemini 3.1 Pro i Gemini 3.1 Flash-Lite to multimodalne modele zaprojektowane do przetwarzania tekstu, obrazów, wideo i kodu. Ich premiera nie jest przypadkowa – odpowiada na rosnące zapotrzebowanie na wydajne i wszechstronne narzędzia AI dla deweloperów i firm. Szczegóły brzmią obiecująco: większa wydajność, rozszerzone okno kontekstowe i zaawansowane możliwości w rozsądnej cenie.
Czym właściwie są nowe modele Gemini 3.1?
W skrócie: to zaawansowane modele sztucznej inteligencji skoncentrowane na multimodalnym przetwarzaniu. Ich głównym zadaniem jest obsługa szerokiego spektrum zadań – od analizy dokumentów i wideo po generowanie kodu i tłumaczenia. Mowa tu o zaawansowanych asystentach dla programistów, systemach analizy treści czy interaktywnych narzędziach edukacyjnych.
Kluczowa jest różnica w przeznaczeniu obu wariantów. Gemini 3.1 Flash-Lite to szybki i tani model tekstowo-multimodalny, stworzony do obsługi ogromnej liczby zadań, takich jak tłumaczenie czy moderacja treści. Gemini 3.1 Pro to bardziej zaawansowany i potężniejszy model, oferujący rozszerzony kontekst i wyższą jakość odpowiedzi w złożonych zastosowaniach. Oba modele stanowią odpowiedź na potrzebę skalowalnych i efektywnych narzędzi AI.
Co potrafią nowe modele? Kluczowe ulepszenia
Google wskazało kilka konkretnych obszarów, w których nowe modele mają być wyraźnie lepsze od swoich poprzedników. Po pierwsze: wydajność i kontekst. Modele oferują lepsze wyniki przy niższych kosztach, a Gemini 3.1 Pro obsługuje wyjątkowo długie okno kontekstowe, co pozwala na analizę bardzo dużych dokumentów, długich nagrań wideo lub rozbudowanych baz kodu w jednym zapytaniu.
Po drugie: wszechstronność multimodalna. Modele zostały wytrenowane tak, by sprawnie łączyć i rozumieć różne rodzaje danych – tekst, obrazy, pliki wideo i audio. W praktyce oznacza to, że AI może analizować zawartość filmu, przetwarzać transkrypcję i odpowiadać na szczegółowe pytania, łącząc informacje ze wszystkich tych źródeł.
Po trzecie: dostępność. Dzięki różnym wersjom – od lekkiego Flash-Lite po zaawansowany Pro – modele są dostosowane do różnych potrzeb i budżetów, co umożliwia szerszą adopcję zaawansowanych możliwości AI.
Bezpieczeństwo i walka z deepfake'ami: SynthID
Google nie zapomniało o rosnącym problemie dezinformacji i deepfake'ów. Technologia znaku wodnego SynthID pozostaje kluczowym elementem ekosystemu. Rozwiązanie opracowane przez Google DeepMind osadza w pliku audio lub obrazie niewykrywalny dla człowieka marker. Pozwala on później sprawdzić, czy dana treść została wygenerowana przez AI.
To ważny krok w stronę odpowiedzialnego rozwoju technologii, zwłaszcza w kontekście ryzyka jej nadużyć. Dla deweloperów integrujących modele oznacza to dodatkową warstwę transparentności i zaufania.
Dla kogo są przeznaczone? Dostęp dla deweloperów i firm
Google udostępnia modele na kilka sposobów, celując w różne grupy odbiorców. Dla programistów i zespołów kluczowy jest dostęp przez Google AI Studio oraz API. To właśnie tam można zacząć eksperymentować z integracją modeli we własnych aplikacjach czy workflowach.
Dla większych organizacji i zastosowań korporacyjnych modele będą dostępne przez Gemini Enterprise na platformie Vertex AI. To ścieżka dla firm, które chcą wdrożyć zaawansowane AI w obsłudze klienta, wewnętrznych systemach analitycznych czy narzędziach deweloperskich.
Wreszcie, przeciętny użytkownik może zetknąć się z ulepszeniami tej technologii w usługach Google, takich jak wyszukiwarka czy asystenci, którzy korzystają z ulepszonych modeli bazowych.
Co na to rynek? Wczesne reakcje
W materiałach promocyjnych Google pochwaliło się współpracą z wczesnymi testerami. Ich opinie sugerują, że modele faktycznie sprawdzają się w integracji z istniejącymi procesami pracy, oferując dużą wydajność i użyteczność.
Warto też zwrócić uwagę na ogólne postępy w benchmarkach multimodalnych, gdzie rodzina modeli Gemini konsekwentnie prezentuje wysoką skuteczność w zadaniach łączących tekst, wideo i kod, co potwierdza ich wszechstronność.
Podsumowanie: kolejny krok w rozwoju multimodalnego AI
Premiera Gemini 3.1 Pro i Flash-Lite nie jest rewolucją, która od razu zmieni wszystko. To raczej konsekwentne i znaczące udoskonalenie w segmencie wydajnych i skalowalnych modeli multimodalnych. Pokazuje jednak wyraźny kierunek, w którym podąża branża: AI ma być wszechstronnym i dostępnym narzędziem do rozwiązywania realnych problemów. Przeniesienie punktu ciężkości na efektywność kosztową, długi kontekst i głębokie zrozumienie multimodalne świadczy o dojrzewaniu tej technologii.
Dla deweloperów i firm specjalizujących się w integracjach AI pojawienie się ulepszonych, łatwo dostępnych modeli to dobra wiadomość. Otwiera nowe możliwości w projektowaniu aplikacji, które mogą rozumieć świat w sposób bardziej zbliżony do człowieka. Sukces tych modeli będzie mierzony nie tyle wynikami w benchmarkach, ile tym, jak wiele firm i użytkowników uzna, że zaawansowane AI stało się praktycznym i niezawodnym elementem ich pracy.
Sprawa, która zaczęła się od dociekliwych pytań użytkowników, przerodziła się w pełnowymiarowy skandal w świecie AI do kodowania. Chodzi o Cursor Composer 2, model reklamowany jako autorski, wewnętrzny przełom startupu Cursor. Okazuje się jednak, że pod maską kryje się fine-tuning otwartoźródłowego modelu chińskiej firmy Moonshot AI – Kimi K2.5. Brak przejrzystości, a nie sam fakt użycia open source’u, wywołał burzę.
Społeczność deweloperska czuje się oszukana, a debata wykracza daleko poza pojedynczy produkt. Dotyka fundamentalnych kwestii etyki w AI, transparentności w biznesie opartym na otwartych modelach oraz rosnącej roli chińskich modeli bazowych w globalnym ekosystemie.
Od podejrzeń do twardych dowodów: Linia czasu afery
Wszystko zaczęło się subtelnie, od obserwacji samych użytkowników. Podejrzenia wyszły na jaw w marcu 2026 roku, gdy niektórzy z nich zauważyli, że odpowiedzi generowane przez Composer 2 wykazują zadziwiające podobieństwa do modelu Kimi K2.5. Chodziło o specyficzną strukturę rozumowania, sposób formułowania odpowiedzi i charakterystyczne wzorce znane z narzędzi Moonshot AI. To były jednak tylko przeczucia.
Prawdziwy przełom nastąpił 19 marca 2026 roku za sprawą programisty znanego jako Fynn. To on przeprowadził techniczną analizę zapytań API. Metoda była prosta, ale skuteczna: przekierował ruch z Cursor IDE na lokalny serwer, który pełnił rolę bazowego adresu URL dla OpenAI. To pozwoliło mu zajrzeć za kulisy komunikacji.
Efekt? Ukryty identyfikator modelu w żądaniach Composer 2 bezpośrednio wskazywał na Kimi K2.5 z dodatkowym fine-tuningiem metodą RL (Reinforcement Learning). To nie były domysły, a twardy, powtarzalny dowód. Dwa dni później, 21 marca, na YouTube pojawiły się szczegółowe analizy, które opisały cały proces premiery. Cursor promował wtedy Composer 2 jako własny model, który ma przewyższać nawet wiodące rozwiązania Anthropic, takie jak Claude 3.5 Sonnet, w benchmarkach kodowania, będąc jednocześnie tańszym. O bazie Kimi nie padło ani słowo.
Niepodważalne dowody techniczne: Tokenizer i identyfikatory
Co konkretnie udowodniono? Przede wszystkim zgodność tokenizera. Tokenizer to kluczowy komponent modelu językowego, który dzieli tekst na jednostki. Jak potwierdzili później pracownicy Moonshot AI, tokenizer użyty w Composer 2 jest identyczny z tym, którego używa Kimi K2.5. To jak znalezienie tego samego odcisku palca na dwóch różnych narzędziach – mocny dowód na wspólne pochodzenie.
Dodatkowo analiza API ujawniła ukryty model ID, jednoznacznie powiązany z Kimi. Cursor przedstawiał wyniki benchmarków, wskazując na duże ulepszenia, na przykład +21,5% w Terminal Bench. Jednak gdy przyjrzeć się surowym danym, okazało się, że benchmarki te znacząco różniły się od tych używanych dla Kimi, a ogólny wzrost wydajności był znaczący (np. wynik 61,3 vs. 44,2 w CursorBench). Sugerowało to, że lwia część możliwości modelu pochodziła nie tylko z zaawansowanej, otwartoźródłowej bazy od Moonshot, ale także z własnego treningu Cursor, który pochłonął większość użytej mocy obliczeniowej.
Warto zaznaczyć, że poprzednia wersja, Composer 1 (lub 1.5), opierała się na innym modelu – Qwen. Dopiero Composer 2 w pełni przesiadł się na Kimi, co czyniło brak wzmianki o tym fakcie jeszcze bardziej rażącym.
Reakcje kluczowych graczy: Przyznanie się i partnerstwo
Po ujawnieniu sprawy Cursor nie mógł już milczeć. Lee Robinson, wiceprezes ds. edukacji deweloperów w Cursor, odniósł się do sprawy na platformie X (dawniej Twitter). Jego komentarz był połączeniem przyznania się do błędu i potwierdzenia legalności działań. „Jestem wielkim zwolennikiem open source… To był błąd, że nie wspomnieliśmy o bazie Kimi w naszym wpisie na blogu od samego początku. Naprawimy to przy kolejnym modelu” – napisał. Jednocześnie podkreślił, że zespół Moonshot AI potwierdził, iż użycie było licencjonowane.
To ostatnie to kluczowy punkt. Moonshot AI/Kimi oficjalnie potwierdzili istnienie partnerskiej, autoryzowanej umowy handlowej pomiędzy Cursor a nimi, zawartej za pośrednictwem platformy Fireworks AI. Z prawnego punktu widzenia Cursor prawdopodobnie nie złamał licencji Kimi K2.5, o ile ta dopuszcza komercyjne użycie. Problem leżał jednak w warstwie etycznej i wizerunkowej, a nie prawnej.
Wściekłość społeczności: Dlaczego deweloperzy poczuli się oszukani?
Reakcja społeczności była szybka i pełna oburzenia. Na forach i w komentarzach podkreślano jeden główny zarzut: brak transparentności. Użytkownicy płacili za funkcjonalność w Cursor IDE, wierząc, że finansują rozwój przełomowego, autorskiego modelu startupu. Tymczasem, jak to ujął jeden z komentatorów na YouTube, okazało się, że „Cursor opakowuje open source i odsprzedaje go” w swoim forku VS Code.
Problemem nie było więc użycie otwartego modelu – to powszechna praktyka. Chodziło o stworzenie wrażenia czegoś zupełnie nowego, zbudowanego samodzielnie od zera. To podważa zaufanie. Jeśli deweloperzy nie mogą ufać opisom technologii, na której polegają w codziennej pracy, na czym ma się opierać cały rynek narzędzi AI do kodowania?
Na forum Hacker News pojawiły się nawet spekulacje, czy gigant AI, Anthropic, nie zdecyduje się na zablokowanie Cursor na swoich platformach. Powód? Moonshot AI, twórca Kimi, figuruje na liście firm związanych z tzw. „kampanią ataków destylacyjnych” (distillation attack campaign), obok OpenAI i xAI. Jak dotąd (stan na koniec marca 2026) żaden taki zakaz nie został potwierdzony.
Szersze implikacje: Otwarte źródła, chińskie modele i przyszłość AI
Afera z Cursor Composer 2 to nie tylko historia jednego modelu. To symptom większych trendów i napięć w świecie sztucznej inteligencji.
Po pierwsze, jasno pokazuje, że społeczność deweloperska domaga się nowych standardów transparentności. Wskazana została paląca potrzeba publikowania jawnych „kart modelu” (model cards) i dokumentacji, które wprost wymieniają modele bazowe, nawet jeśli mowa tylko o fine-tuningu. Chodzi o uczciwość intelektualną, która pozwala użytkownikom dokonywać świadomych wyborów.
Po drugie, sprawa rzuca światło na rosnącą dominację chińskich modeli bazowych, takich jak Kimi, Qwen czy DeepSeek, w globalnym ekosystemie open source. Są one często darmowe, potężne i łatwo dostępne. Firma z Doliny Krzemowej, taka jak Cursor, może na nich budować swoją wartość. To budzi mieszane uczucia w kontekście geopolitycznym i zmusza do pytań o długoterminową niezależność technologiczną Zachodu. Niektórzy politycy już ostrzegają przed chińską dominacją w obszarze open-source AI.
Po trzecie, kwestionuje to model biznesowy małych, zwinnych zespołów, które budują narzędzia na cudzych, otwartych fundamentach. Jeśli ich główną wartością jest tylko opakowanie i fine-tuning, jak mogą konkurować, gdy dostawcy modeli bazowych zaczną oferować podobne usługi bezpośrednio? Rynek agentów kodujących rozwija się błyskawicznie, a zaufanie jest tu kluczowym aktywem, który łatwo stracić.
Podsumowanie: Lekcja na przyszłość
Afera Cursor Composer 2 wciąż się rozwija, ale już dostarczyła ważnej lekcji dla całej branży. Legalne użycie otwartoźródłowego modelu to za mało. W erze, w której fundamentem innowacji jest współdzielona praca tysięcy badaczy i inżynierów, przejrzystość staje się nową walutą zaufania.
Cursor przyznał się do przeoczenia w kwestii atrybucji, ale nie wystosował pełnych przeprosin ani nie zrewidował szczegółowo swojej dokumentacji. To może być dla nich kosztowny błąd wizerunkowy. Dla deweloperów natomiast jest to wyraźny sygnał, by podchodzić do marketingowych deklaracji o „własnych”, „przełomowych” modelach z dużą dozą zdrowego sceptycyzmu i domagać się technicznych szczegółów.
Ostatecznie ta historia nie kończy się na Kimi czy Cursorze. To rozdział w szerszej opowieści o tym, jak budujemy etyczny i zrównoważony ekosystem AI, w którym współpraca i otwartość idą w parze z uczciwością wobec tych, którzy z tych technologii korzystają.