Wydana niedawno aktualizacja OpenCode 1.4.11 koncentruje się na usprawnieniach podstawowej infrastruktury tego otwartoźródłowego asystenta kodowania AI. Najnowsze poprawki naprawiają problemy z routingiem przestrzeni roboczych oraz wprowadzają ulepszenia w zarządzaniu sesjami, co przekłada się na bardziej stabilne środowisko dla programistów korzystających z terminala, IDE lub aplikacji desktopowej.
Kluczowe zmiany dotyczą zapewnienia, że żądania API docierają do właściwej instancji workspace'u, co wcześniej bywało źródłem błędów w przepływach tworzenia i synchronizacji. System przestał podejmować niepotrzebne próby synchronizacji sesji, które nigdy nie były udostępniane, co redukuje zbędny narzut operacyjny. Te techniczne poprawki mają realny wpływ na codzienną pracę z AI przy projektach webdev czy DevOps.
Kluczowe punkty aktualizacji
- Naprawa routingu workspace'ów: Poprawiono mechanizm kierowania żądań, aby zawsze trafiały do poprawnej instancji przestrzeni roboczej. Rozwiązano problem, w którym adaptery HTTP API gubiły kontekst instancji, co mogło zakłócać tworzenie, synchronizację i cały przepływ pracy.
- Stabilność zarządzania sesjami: Zablokowano próby synchronizacji udostępniania (
share sync) dla sesji, które nigdy nie były współdzielone. Dodatkowo wprowadzono inne poprawki w API sesji, jak spójne zwracanie błędów dla brakujących sesji. - Usprawnienia infrastrukturalne: W pakiecie znalazły się również inne poprawki, przywracające poprawne działanie formatowania kodu, gdy formatter pisze do stdout/stderr, oraz dodano wpis do menu Ustawienia systemu macOS dla lepszej ergonomii aplikacji desktopowej.
Dlaczego routing workspace'ów ma znaczenie?
OpenCode 1.4.11, jako agent AI działający w terminalu czy edytorze, często pracuje w kontekście wielu równoległych przestrzeni roboczych lub projektów. Usterka w routingu mogła prowadzić do sytuacji, w której komenda wydana dla jednego projektu była wykonywana w zupełnie innym kontekście, co powodowało zamieszanie i potencjalne błędy.
Poprawka w najnowszych zmianach eliminuje ten problem, zapewniając integralność działania funkcji takich jak tworzenie nowego workspace'u, jego synchronizacja czy kierowanie żądań API. Dla programisty oznacza to większą przewidywalność. Gdy wydajesz polecenie, masz pewność, że zostanie ono wykonane tam, gdzie powinno. To kluczowe dla płynnego kodowania i efektywnego wykorzystania AI jako partnera w programowaniu.
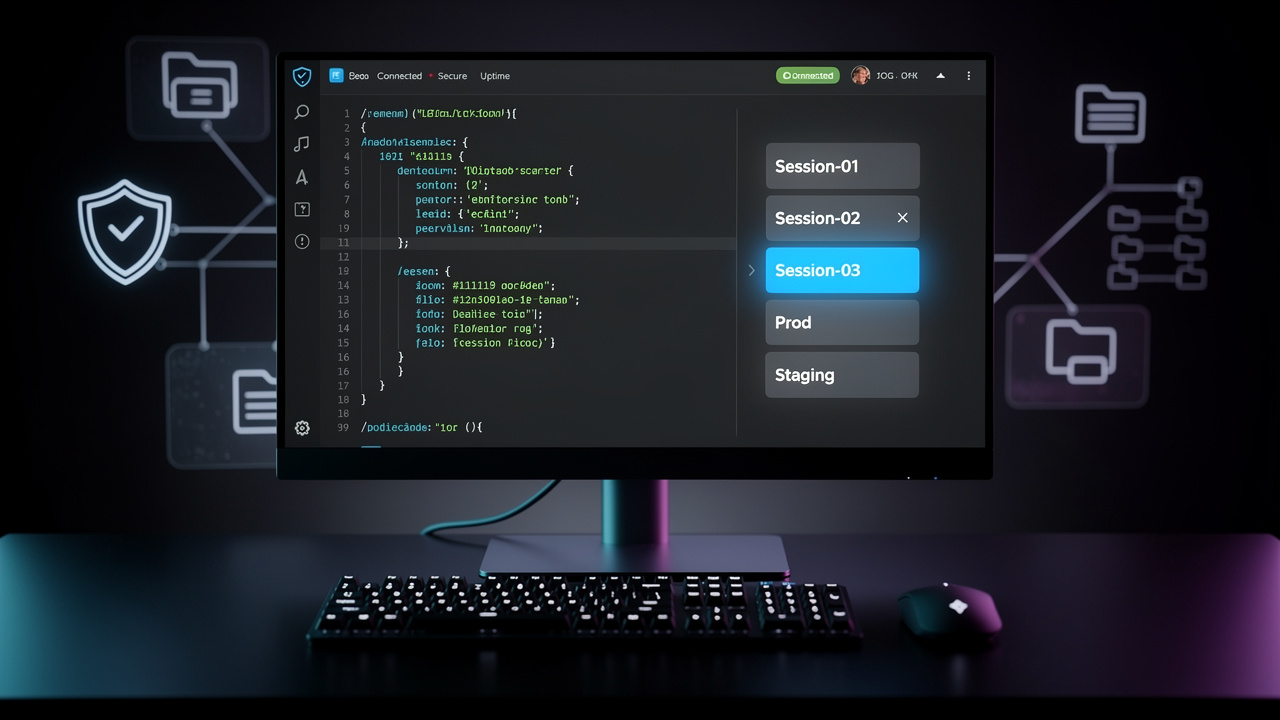
Lepsza kontrola nad sesjami i mniej szumu systemowego

Druga główna zmiana dotyczy optymalizacji zarządzania sesjami. Mechanizm próbujący synchronizować sesje, które nigdy nie były oznaczone do udostępnienia, generował niepotrzebne operacje w tle. W środowiskach wielowątkowych czy przy pracy z wieloma projektami narzut taki mógł wpływać na responsywność.
Teraz to zbędne obciążenie zostało wyeliminowane. System jest bardziej efektywny i nie marnuje zasobów. Dodatkowe poprawki w API sesji v2, jak poprawne kodowanie opcjonalnych pól w odpowiedziach, zwiększają ogólną stabilność i kompatybilność z różnymi klientami i integracjami.
Otwarte ekosystemy i aktualizacje pluginów

Platforma wspiera integrację z popularnymi modelami językowymi, takimi jak Claude, GPT czy Gemini, oraz z edytorami jak Zed. Działa w trybach "build" (pełny dostęp) i "plan" (tylko do odczytu), zawsze pytając o zgodę przed wykonaniem poleceń bash. Te udoskonalenia infrastruktury wspierają takie założenia, czyniąc narzędzie bardziej niezawodnym w codziennym użyciu.
Co to oznacza dla programistów?
Najnowsze poprawki, choć skupione na usprawnieniach "pod maską", są ważne dla każdego, kto używa OpenCode 1.4.11 do poważnej pracy. Stabilność routingu eliminuje frustrujące, trudne do debugowania błędy kontekstu. Lepsze zarządzanie sesjami sprawia, że aplikacja działa bardziej responsywnie.
Dla zespołów zajmujących się web developmentem czy DevOps te zmiany przekładają się na mniej przestojów i większą płynność współpracy z AI. Otwartoźródłowy charakter projektu pozwala na głębszą integrację z własnym stackiem technologicznym i hostingiem. Kolejne wydania, które regularnie się pojawiają, budują na tych solidnych fundamentach, dodając nowe funkcje i dalsze udoskonalenia.