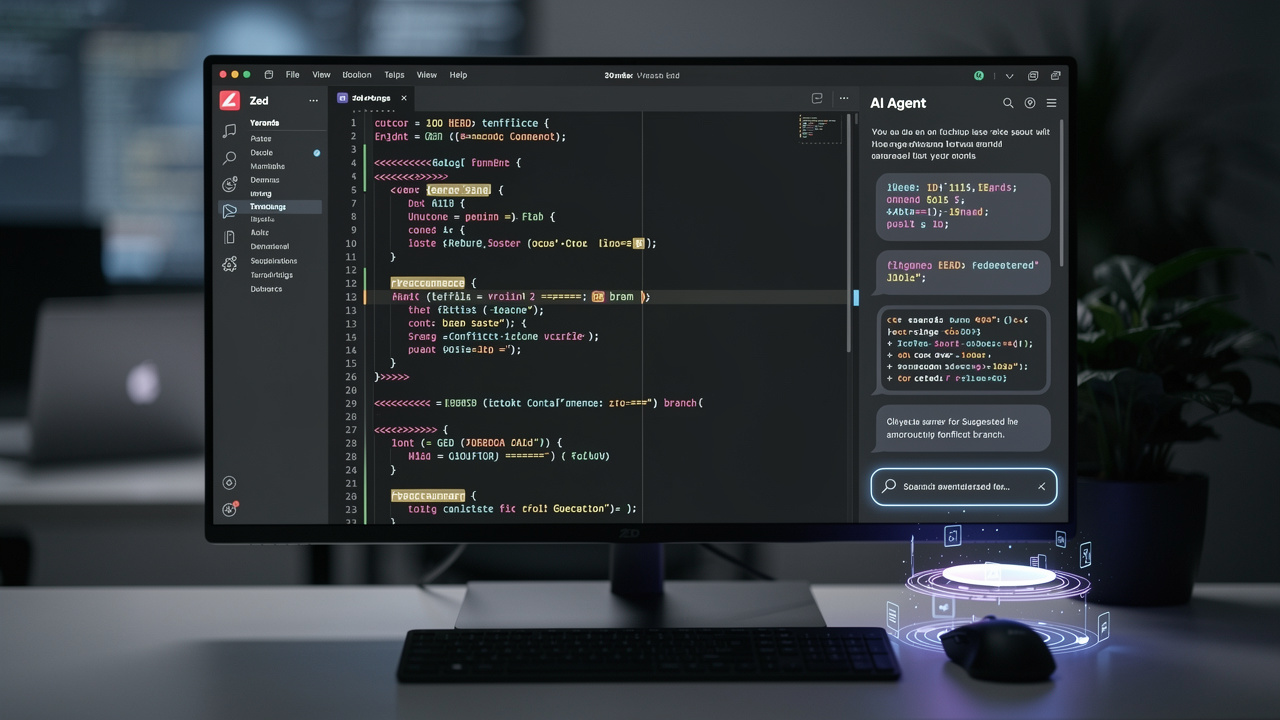
Wydanie Zed 0.228.0 przynosi powiew świeżego powietrza dla każdego, kto regularnie mierzy się z największym koszmarem współpracy w Git: konfliktami scalania. To nie kolejna drobna aktualizacja, lecz pakiet usprawnień celujących w konkretne, bolesne punkty współczesnego workflow deweloperskiego. Najważniejszym bohaterem jest oczywiście AI, ale nie brakuje też praktycznych ulepszeń w zarządzaniu worktree i poprawek dla systemu Windows.
Agent AI jako mediator: automatyczne rozwiązywanie konfliktów merge
To chyba najgłośniejsza nowość. Zed wprowadza możliwość automatycznego rozwiązywania konfliktów merge bezpośrednio przez panel Agenta. Kiedy Git zgłosi konflikt podczas scalania gałęzi, zamiast mozolnie analizować ręcznie pliki .diff, możesz teraz po prostu poprosić o pomoc wbudowaną sztuczną inteligencję.
Mechanizm jest prosty. Wystarczy otworzyć panel Agenta i wydać mu polecenie w stylu „rozwiąż ten konflikt merge” lub bardziej szczegółową instrukcję. Agent przeanalizuje skonfliktowane pliki, zrozumie intencje zmian z obu gałęzi i zaproponuje rozwiązanie. To ogromna oszczędność czasu i nerwów, szczególnie w dużych projektach, gdzie konflikty bywają skomplikowane i pojawiają się w wielu plikach naraz.
Co istotne, funkcja ta nie działa jak magiczna różdżka, która zawsze ma rację. Deweloper nadal ma pełną kontrolę i wgląd w to, co Agent proponuje. Może zaakceptować sugestię, zmodyfikować ją lub odrzucić. To potężne narzędzie wspomagające, które zdejmuje z programisty ciężar żmudnej, mechanicznej części pracy, pozwalając skupić się na logice biznesowej.
@branch-diff: kontekst całej gałęzi na żądanie
Druga główna innowacja AI dotyczy dostarczania kontekstu. Wcześniej, aby Agent mógł pomóc z konkretnym fragmentem kodu, trzeba było mu ręcznie dostarczyć odpowiednie pliki lub ich fragmenty. W wersji 0.228.0 wprowadzono możliwość @-wzmiankowania diffa całej gałęzi.
W praktyce, wpisując w panelu Agenta @branch-diff, automatycznie dołączasz do kontekstu wszystkie zmiany wprowadzone w bieżącej gałęzi od momentu odłączenia od bazy (np. `main` lub `master`). To genialnie proste, a jednocześnie niezwykle skuteczne rozwiązanie.
Dzięki temu, prosząc Agenta o pomoc – czy to przy refaktoryzacji, pisaniu testu, czy wyjaśnianiu kodu – masz pewność, że AI widzi pełny obraz Twojej pracy, a nie tylko wycinek z jednego pliku. Fundamentalnie poprawia to jakość i trafność sugestii, ponieważ model rozumie szerszy kontekst wprowadzanych funkcjonalności.
Usprawnienia dla workflow z Git worktree
Jeśli używasz Git worktree do równoległej pracy nad różnymi gałęziami, nowy Zed przynosi kilka bardzo wyczekiwanych usprawnień. Zarządzanie nimi staje się znacznie prostsze bez ciągłego sięgania do terminala.
Po pierwsze, dodano możliwość usuwania worktree bezpośrednio z selektora gałęzi (branch picker). Wystarczy użyć skrótu klawiszowego (Cmd+Shift+Backspace na macOS, Ctrl+Shift+Backspace na Linux/Windows) w oknie wyboru worktree. To drobna zmiana, która znacznie redukuje liczbę niepotrzebnych przełączeń kontekstu.
Po drugie, co jest kluczowe dla deweloperów pracujących zdalnie, Zed 0.228.0 dodaje wsparcie dla operacji na worktree przez połączenia SSH. Teraz możesz bezpiecznie usuwać i zmieniać nazwy worktree również wtedy, gdy projekt znajduje się na zdalnym serwerze, a Ty łączysz się z nim przez SSH. To bezpośrednia odpowiedź na problemy w rozproszonych konfiguracjach DevOps.
Myślenie na głos, LM Studio i czysty tekst
Aktualizacja 0.228.0 przynosi też garść innych ulepszeń dla Agenta, które warto odnotować. Dla użytkowników modeli Anthropic (jak Claude) poprzez integrację z Copilotem włączono tryb „thinking”. Modele mogą teraz prezentować swoją wewnętrzną, rozbudowaną argumentację przed podaniem finalnej odpowiedzi, co często prowadzi do dokładniejszych i lepiej uzasadnionych rezultatów.
Dla fanów lokalnych modeli LLM dodano nowe ustawienia api_url i api_key dla dostawcy LM Studio. Ułatwia to konfigurację i integrację z własnymi, hostowanymi lokalnie modelami językowymi.
Nie zabrakło też małej, acz użytecznej opcji w interfejsie. W edytorze wiadomości panelu Agenta pojawiła się nowa pozycja w menu kontekstowym: „Paste as Plain Text” (Wklej jako czysty tekst). To rozwiązanie irytującego problemu, gdy wklejając fragment kodu czy błąd z przeglądarki, niechcący przenosimy formatowanie, które mogłoby zakłócać działanie Agenta.
Lepszy podgląd Markdown i nowe API dla rozszerzeń
Poza głównymi atrakcjami wydanie zawiera szereg innych poprawek. Dla osób dokumentujących kod lub piszących w Markdown ważna będzie poprawa wydajności podglądu plików `.md`. Zed zoptymalizował sposób aktualizowania podglądu, szczególnie po zaznaczaniu lub odznaczaniu elementów na listach zadań. Podgląd reaguje teraz szybciej i płynniej.
Dla twórców rozszerzeń otwierają się nowe możliwości. W API rozszerzeń pojawiło się wsparcie dla schematów ustawień z autouzupełnianiem, przeznaczone do konfiguracji serwerów językowych (LSP). Pozwala to twórcom rozszerzeń na definiowanie struktury swoich ustawień w sposób, który Zed będzie rozumiał i mógł prezentować użytkownikowi w przyjaznej formie z podpowiedziami.
Dodano także kernel_language_names dla kerneli Jupyter, co ułatwia integrację z notatnikami IPython.
Naprawy błędów, głównie z myślą o Windows
Każde stabilne wydanie niesie ze sobą solidną porcję poprawek i 0.228.0 nie jest wyjątkiem. Szczególną uwagę poświęcono środowisku Windows. Naprawiono między innymi problemy z wyświetlaniem komunikatów o błędach w czatach OpenAI/Copilot oraz poprawiono wykrywanie ścieżek przy Ctrl+kliknięcie w terminalu, gdy te zawierały prefiksy takie jak 0:.
Wyeliminowano też kilka problemów związanych z AI. Przycisk „View AI Settings” na stronie powitalnej działa już poprawnie, gdy AI jest wyłączone. Naprawiono także połączenia z serwerami MCP (Model Context Protocol), które wcześniej mogły kończyć się niepowodzeniem przy dezaktywowanej sztucznej inteligencji.
Dlaczego te zmiany są istotne dla web dewelopera i zespołu DevOps?
Wydanie Zed 0.228.0 nie jest przypadkowym zbiorem funkcji. To spójna odpowiedź na wyzwania współczesnego programowania, gdzie łączy się praca zespołowa (stąd konflikty merge), eksperymentowanie z różnymi funkcjami równolegle (stąd worktree) i dążenie do maksymalnej produktywności poprzez automatyzację (stąd AI).
Dla web dewelopera pracującego w frameworkach takich jak React, Vue czy przy aplikacjach backendowych, automatyczne rozwiązywanie konfliktów i łatwy dostęp do diffa całej gałęzi to narzędzia, które realnie skracają czas poświęcany na „składanie kodu w całość”. Dzięki temu można bardziej skupić się na implementacji logiki.
Dla specjalisty DevOps czy osób zajmujących się hostingiem, wsparcie SSH dla operacji na worktree to konkretne ułatwienie w zarządzaniu środowiskami deweloperskimi i stagingowymi na zdalnych serwerach. To kolejny krok w stronę tego, by cały workflow Git, nawet w złożonych, zdalnych konfiguracjach, dało się obsłużyć wygodnie z poziomu jednego edytora.
Warto przypomnieć, że Zed od początku stawia na prywatność w kontekście AI. Domyślnie żadne prompty ani fragmenty kodu nie są przechowywane przez twórców edytora, a dane są wysyłane tylko do wybranego przez użytkownika dostawcy LLM (Anthropic, OpenAI, LM Studio itp.). Nowe funkcje w 0.228.0 wpisują się w tę filozofię, oferując potężne narzędzia bez kompromisów w zakresie bezpieczeństwa kodu.
Podsumowanie
Zed 0.228.0 to wydanie, które mocno stawia na automatyzację najbardziej uciążliwych aspektów pracy z Gitem, jednocześnie wprowadzając praktyczne usprawnienia codziennego workflow. Przeniesienie ciężaru rozwiązywania konfliktów merge na AI, choć wymaga zachowania czujności, jest krokiem w stronę przyszłości, w której programista staje się bardziej architektem niż rzemieślnikiem mozolnie łączącym fragmenty kodu.
Dodanie głębokiego kontekstu poprzez @branch-diff oraz ulepszenia w zarządzaniu worktree, szczególnie przez SSH, pokazują, że zespół Zed dobrze rozumie realne problemy w dużych, rozproszonych projektach. To nie są funkcje na pokaz, lecz konkretne narzędzia rozwiązujące realne bolączki. W połączeniu z ciągłymi poprawkami stabilności i wydajności tworzy to obraz edytora, który konsekwentnie ewoluuje, by stać się centrum efektywnego procesu tworzenia oprogramowania.
