Deweloperzy korzystający z Gemini CLI, terminalowego asystenta AI od Google, otrzymali nową wersję do testów. Wydanie v0.36.0-preview.0 kontynuuje trend wzmacniania zabezpieczeń i ergonomii pracy, zapoczątkowany we wcześniejszych wersjach nightly. Wersja preview skupia się na bezpiecznej interakcji z przeglądarką oraz na usprawnieniach interfejsu użytkownika, oferując jednocześnie konkretne wytyczne dotyczące aktualizacji.
Kluczowe ulepszenia w bezpieczeństwie i prywatności
Najważniejszym filarem tej wersji preview są funkcje mające na celu ochronę użytkownika podczas pracy z agentami. Pojawiły się mechanizmy kontroli dostępu dla agenta przeglądarki, co stanowi istotny krok w zarządzaniu sesjami webowymi. System wprowadza też kontrolę wrażliwych akcji, które mogą mieć daleko idące konsekwencje. To rozwinięcie wcześniejszych mechanizmów zarządzania politykami (policies).
Dodatkowo usprawniono metadane dotyczące użycia tokenów API, co ułatwia audyt i monitorowanie. Dla zespołów korzystających z zaawansowanych konfiguracji dostępne jest teraz uwierzytelnianie przez centralny panel kontrolny. Wszystkie te zmiany wskazują na dojrzałe podejście do izolacji narzędzi i egzekwowania polityk bezpieczeństwa w dynamicznym środowisku AI.
Usprawnienia interfejsu i workflow
Poza bezpieczeństwem wersja v0.36.0-preview.0 przynosi szereg udogodnień w codziennej pracy dewelopera. Odświeżono układ edytora, poprawiając czytelność i organizację przestrzeni roboczej. Ciekawą nowością jest obsługa Git worktree, która pozwala na izolowanie sesji Gemini CLI w różnych kontekstach gałęzi Gita bez konieczności przełączania repozytoriów.
Zoptymalizowano czas uruchamiania przy użyciu flagi --version oraz uproszczono obsługę zdarzeń klawiatury i myszy. CLI zyskało również bardziej elastyczne rozwiązywanie modeli dynamicznych oraz rozszerzone ostrzeżenia o fallbacku terminala. Dla twórców agentów wsparcie dla konfiguracji ułatwia teraz pracę z agentami zdalnymi.
Praktyczne wskazówki: jak bezpiecznie aktualizować i śledzić zmiany
Przy tak szybkim tempie rozwoju twórcy podkreślają potrzebę zachowania ostrożności. W środowiskach testowych można używać opcji automatycznej aktualizacji, ale kluczowe jest monitorowanie oficjalnych wydań na GitHubie pod kątem poprawek.
Aby w pełni wykorzystać nowe funkcje bezpieczeństwa, warto aktywnie korzystać z flagi --policy i restrykcyjnych profili sandboxingu. Użytkownicy chcący testować najnowsze integracje powinni włączyć odpowiednie funkcje w ustawieniach.
Śledzenie zmian ułatwiają changelogi dostępne w dokumentacji oraz szczegółowe informacje w pull requestach na GitHubie. W przypadku długich sesji nowe mechanizmy kontroli wrażliwych akcji pomagają zapobiegać problemom, takim jak niebezpieczne rzutowania czy błędy związane z wyczerpaniem pamięci (OOM).
Podsumowanie: kolejny krok w ewolucji Gemini CLI
Wersja v0.36.0-preview.0 to nie rewolucja, a konsekwentne dopracowywanie narzędzia, które staje się coraz bardziej niezawodne i bezpieczne. Skupienie na zabezpieczeniach agenta przeglądarki pokazuje, że rozwój podąża za realnymi przypadkami użycia w zadaniach web deweloperskich i AI. Jednocześnie usprawnienia CLI, takie jak wsparcie dla Git worktree, świadczą o zrozumieniu potrzeb złożonych procesów programistycznych.
Szybkie tempo wydań preview zachęca do testowania, jednak zawsze z zachowaniem ostrożności i w oparciu o rekomendowane praktyki aktualizacji. Gemini CLI umacnia swoją pozycję jako profesjonalne narzędzie open-source, które łączy potencjał modeli językowych z praktycznością terminala.
W najnowszym wydaniu narzędzie Gemini API otrzymuje szereg istotnych aktualizacji skupionych na udostępnieniu nowych modeli i zwiększeniu ich możliwości. Sercem zmian jest wprowadzenie modeli z rozszerzonym oknem kontekstowym, które mają na celu przezwyciężenie kluczowych ograniczeń wcześniejszych wersji. Jednocześnie pojawiają się usprawnienia w aplikacjach i interfejsach korzystających z tych modeli, nastawione na poprawę doświadczeń użytkownika (user experience).
Rozszerzone możliwości modeli: większy kontekst i specjalizacja
Dotychczasowe modele Gemini, choć potężne, miały ograniczenia związane z pojemnością okna kontekstowego. Najnowsze aktualizacje wprowadzają modele z oknem kontekstowym sięgającym 1 miliona tokenów, co pozwala na pracę z bardzo obszernymi fragmentami kodu i dokumentacji. Ta zmiana ma bezpośredni wpływ na wydajność wykonywania złożonych, wieloetapowych zadań bez utraty kontekstu.
Kluczowe elementy tych aktualizacji to:
Modele z rozszerzonym kontekstem: Udostępnienie modeli takich jak Gemini 1.5 Pro i Flash z oknem 1M tokenów umożliwia analizę długich dokumentów, dużych baz kodu lub prowadzenie rozbudowanych konwersacji bez potrzeby częstego podsumowywania treści.
Specjalizacja zadań: Twórcy promują wykorzystanie różnych modeli do konkretnych typów zadań – szybszych i tańszych (np. Flash) do prostszych operacji, a bardziej zaawansowanych (np. Pro) do złożonego rozumowania i planowania.
Integracje i protokoły: Rozwój ekosystemu wokół API, w tym eksperymentalne wsparcie dla protokołów takich jak MCP (Model Context Protocol), może w przyszłości otworzyć drogę do tworzenia zaawansowanych procesów agentowych, łączących różne źródła danych i narzędzia.
Co to oznacza dla programistów? Praktyczny wpływ na workflow
Ewolucja modeli ma konkretne przełożenie na codzienną pracę, szczególnie w obszarach takich jak web development, AI czy analiza danych. Dzięki rozszerzonemu kontekstowi aplikacje oparte na Gemini API mogą teraz efektywniej obsługiwać skomplikowane, wieloetapowe zadania.
Wyobraźmy sobie zadanie, w którym asystent analizuje całe repozytorium kodu w poszukiwaniu określonego wzorca, przetwarza długą dokumentację techniczną, a następnie generuje na tej podstawie plan refaktoryzacji – wszystko w ramach jednej, spójnej sesji. Praca z tak dużym kontekstem minimalizuje potrzebę ręcznego dzielenia problemów na mniejsze części.
Rozwój ekosystemu i integracje z popularnymi narzędziami zwiększają użyteczność API, umożliwiając automatyzację zadań związanych z analizą kodu czy generowaniem treści. Ponadto dostępność różnych modeli pozwala na optymalizację kosztów i wydajności w zależności od potrzeb projektu.
Ulepszenia aplikacji: lepsza kontrola i interakcja
Równolegle do rozwoju samych modeli aplikacje i interfejsy korzystające z Gemini otrzymują pakiet usprawnień skupionych na użytkowniku. Kluczową koncepcją, która zyskuje na znaczeniu, jest idea planowania przed działaniem.
Coraz więcej narzędzi promuje tryb pracy pozwalający najpierw bezpiecznie przeanalizować kod i wygenerować plany działania, zanim użytkownik zatwierdzi jakiekolwiek modyfikacje. Asystent może zadawać pytania doprecyzowujące i tworzyć szczegółowe plany, na przykład dla migracji całej aplikacji, dając programiście pełną kontrolę i wgląd w proponowane zmiany. To ważny krok w stronę zwiększenia bezpieczeństwa i zaufania do narzędzi AI.
Poza tym odświeżane są interfejsy użytkownika, wprowadzane są ulepszenia w komunikacji z modelem oraz lepsza integracja ze środowiskiem programistycznym (IDE). Personalizacja doświadczeń wynika z ogólnych ulepszeń aplikacji, które obejmują też bardziej przejrzyste komunikaty i trwałość stanu sesji.
Ewolucja modeli Gemini i ich ekosystemu to fundamentalna zmiana w możliwościach asystentów programistycznych. Przejście w stronę modeli o ogromnej pojemności kontekstu bezpośrednio rozwiązuje problemy deweloperów przy automatyzacji złożonych procesów (workflow) wymagających szerokiego spojrzenia na projekt.
Połączenie technicznej głębi z praktycznymi ulepszeniami w interakcji, takimi jak nacisk na planowanie i kontrolę, pokazuje zrównoważone podejście do rozwoju. Narzędzia oparte na Gemini nie tylko stają się potężniejsze pod maską, ale także dążą do większej przewidywalności i bezpieczeństwa. Te zmiany wyraźnie wyznaczają trend w ewolucji asystentów: w stronę większej zdolności rozumienia złożonych kontekstów, lepszej współpracy z człowiekiem i integracji w ramach wieloetapowych procesów.
Kolejna aktualizacja Claude Code, oznaczona numerem wersji 2.1.80, przynosi znaczące usprawnienia w dwóch kluczowych dla programistów obszarach: zarządzaniu wtyczkami i monitorowaniu zużycia zasobów. To nie tylko kosmetyczne poprawki, ale zmiany, które realnie wpływają na codzienną pracę z tym asystentem AI.
Choć oficjalne release notes są dość oszczędne w szczegóły, udało się wyłuskać najważniejsze nowości i poprawki, które trafiły do narzędzia. Wersja 2.1.80 skupia się na większej przejrzystości i wygodzie, zwłaszcza dla osób, które intensywnie korzystają z Claude.ai i rozbudowują swoje środowisko o dodatkowe funkcje.
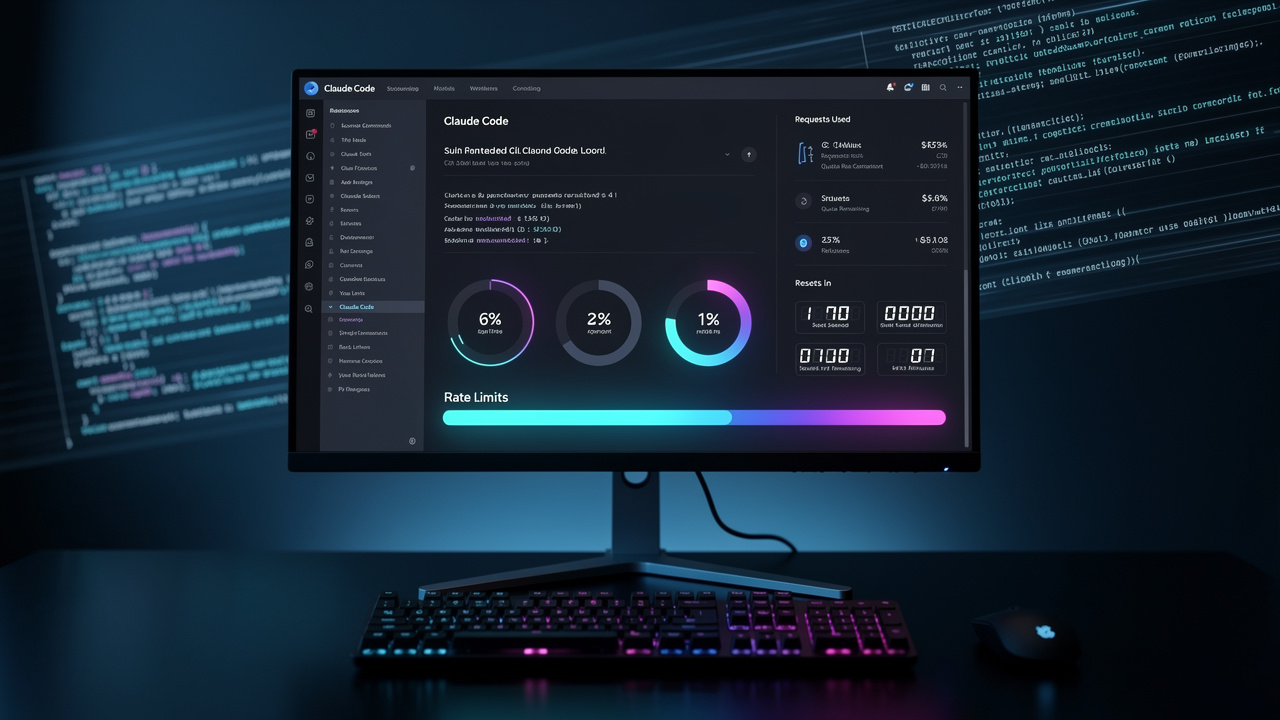
Monitoring rate limitów bezpośrednio w statusline
Jedną z najbardziej praktycznych nowości jest dodanie monitorowania limitów (rate limits) API Claude.ai bezpośrednio do paska statusu. Do skryptów statusline dodano nowe pole rate_limits, które wyświetla wykorzystanie limitów w dwóch horyzontach czasowych: pięciogodzinnym oknie kroczącym i tygodniowym pułapie.
Co to oznacza w praktyce? Programiści mogą teraz na bieżąco śledzić used_percentage – czyli procent wykorzystanego limitu – oraz sprawdzać znacznik czasowy resets_at, który informuje, kiedy limity zostaną zresetowane. To cenna informacja, zwłaszcza dla zespołów pracujących nad większymi projektami, gdzie zużycie tokenów i godzin obliczeniowych może szybko rosnąć.
Warto przypomnieć, że Claude Code działa w systemie dwupoziomowym. Pierwsza warstwa to pięciogodzinne okno kroczące, które kontroluje aktywność w krótkich seriach. Druga to tygodniowy limit, który ogranicza całkowitą liczbę aktywnych godzin obliczeniowych. Dla planu Pro przekłada się to na około 40–80 godzin tygodniowo przy użyciu modeli Sonnet, a najwyższy plan Max oferuje nawet do 480 godzin Sonnet lub 40 godzin Opus – w zależności od liczby równoległych sesji i złożoności modeli.
Podgląd nowej funkcji: Kanały (Channels)
Wersja 2.1.80 wprowadza nową, eksperymentalną funkcję oznaczoną jako research preview. Chodzi o flagę --channels, która umożliwia serwerom MCP bezpośrednie przesyłanie wiadomości do sesji użytkownika. Ta nowa funkcja pozwala na kontrolę asystenta przez zewnętrzne kanały, takie jak Telegram czy Discord, i wymaga logowania przez claude.ai (klucze API nie są obsługiwane).
Na razie to tylko zapowiedź możliwości, ale kierunek jest ciekawy. Taki mechanizm może pozwolić na bardziej dynamiczne interakcje, np. otrzymywanie powiadomień z systemów CI/CD, alertów monitoringu czy wiadomości z czatów zespołowych bezpośrednio w interfejsie Claude Code.
Podsumowanie
Aktualizacja Claude Code do wersji 2.1.80 nie jest rewolucją, ale solidnym krokiem w ewolucji narzędzia. Skupia się na tym, co ważne dla programistów na co dzień: przejrzystości (rate limits) i nowych możliwościach integracji (kanały).
Nowy system monitoringu limitów to odpowiedź na realną potrzebę użytkowników, którzy chcą kontrolować koszty i zużycie zasobów. Eksperymentalna funkcja kanałów pokazuje kierunek rozwoju w stronę bardziej dynamicznej i zintegrowanej komunikacji.
Wersja 2.1.80 utrzymuje trend, w którym Claude Code staje się nie tylko asystentem AI, ale coraz bardziej zintegrowanym środowiskiem deweloperskim, które dba o widoczność kluczowych metryk i oferuje sensowne, pragmatyczne ulepszenia interfejsu.
26 lutego 2026 roku Google wprowadził do oferty nowe modele, które mają odmienić sposób, w jaki wchodzimy w interakcje z maszynami. Gemini 3.1 Pro i Gemini 3.1 Flash-Lite to multimodalne modele zaprojektowane do przetwarzania tekstu, obrazów, wideo i kodu. Ich premiera nie jest przypadkowa – odpowiada na rosnące zapotrzebowanie na wydajne i wszechstronne narzędzia AI dla deweloperów i firm. Szczegóły brzmią obiecująco: większa wydajność, rozszerzone okno kontekstowe i zaawansowane możliwości w rozsądnej cenie.
Czym właściwie są nowe modele Gemini 3.1?
W skrócie: to zaawansowane modele sztucznej inteligencji skoncentrowane na multimodalnym przetwarzaniu. Ich głównym zadaniem jest obsługa szerokiego spektrum zadań – od analizy dokumentów i wideo po generowanie kodu i tłumaczenia. Mowa tu o zaawansowanych asystentach dla programistów, systemach analizy treści czy interaktywnych narzędziach edukacyjnych.
Kluczowa jest różnica w przeznaczeniu obu wariantów. Gemini 3.1 Flash-Lite to szybki i tani model tekstowo-multimodalny, stworzony do obsługi ogromnej liczby zadań, takich jak tłumaczenie czy moderacja treści. Gemini 3.1 Pro to bardziej zaawansowany i potężniejszy model, oferujący rozszerzony kontekst i wyższą jakość odpowiedzi w złożonych zastosowaniach. Oba modele stanowią odpowiedź na potrzebę skalowalnych i efektywnych narzędzi AI.
Co potrafią nowe modele? Kluczowe ulepszenia
Google wskazało kilka konkretnych obszarów, w których nowe modele mają być wyraźnie lepsze od swoich poprzedników. Po pierwsze: wydajność i kontekst. Modele oferują lepsze wyniki przy niższych kosztach, a Gemini 3.1 Pro obsługuje wyjątkowo długie okno kontekstowe, co pozwala na analizę bardzo dużych dokumentów, długich nagrań wideo lub rozbudowanych baz kodu w jednym zapytaniu.
Po drugie: wszechstronność multimodalna. Modele zostały wytrenowane tak, by sprawnie łączyć i rozumieć różne rodzaje danych – tekst, obrazy, pliki wideo i audio. W praktyce oznacza to, że AI może analizować zawartość filmu, przetwarzać transkrypcję i odpowiadać na szczegółowe pytania, łącząc informacje ze wszystkich tych źródeł.
Po trzecie: dostępność. Dzięki różnym wersjom – od lekkiego Flash-Lite po zaawansowany Pro – modele są dostosowane do różnych potrzeb i budżetów, co umożliwia szerszą adopcję zaawansowanych możliwości AI.
Bezpieczeństwo i walka z deepfake'ami: SynthID
Google nie zapomniało o rosnącym problemie dezinformacji i deepfake'ów. Technologia znaku wodnego SynthID pozostaje kluczowym elementem ekosystemu. Rozwiązanie opracowane przez Google DeepMind osadza w pliku audio lub obrazie niewykrywalny dla człowieka marker. Pozwala on później sprawdzić, czy dana treść została wygenerowana przez AI.
To ważny krok w stronę odpowiedzialnego rozwoju technologii, zwłaszcza w kontekście ryzyka jej nadużyć. Dla deweloperów integrujących modele oznacza to dodatkową warstwę transparentności i zaufania.
Dla kogo są przeznaczone? Dostęp dla deweloperów i firm
Google udostępnia modele na kilka sposobów, celując w różne grupy odbiorców. Dla programistów i zespołów kluczowy jest dostęp przez Google AI Studio oraz API. To właśnie tam można zacząć eksperymentować z integracją modeli we własnych aplikacjach czy workflowach.
Dla większych organizacji i zastosowań korporacyjnych modele będą dostępne przez Gemini Enterprise na platformie Vertex AI. To ścieżka dla firm, które chcą wdrożyć zaawansowane AI w obsłudze klienta, wewnętrznych systemach analitycznych czy narzędziach deweloperskich.
Wreszcie, przeciętny użytkownik może zetknąć się z ulepszeniami tej technologii w usługach Google, takich jak wyszukiwarka czy asystenci, którzy korzystają z ulepszonych modeli bazowych.
Co na to rynek? Wczesne reakcje
W materiałach promocyjnych Google pochwaliło się współpracą z wczesnymi testerami. Ich opinie sugerują, że modele faktycznie sprawdzają się w integracji z istniejącymi procesami pracy, oferując dużą wydajność i użyteczność.
Warto też zwrócić uwagę na ogólne postępy w benchmarkach multimodalnych, gdzie rodzina modeli Gemini konsekwentnie prezentuje wysoką skuteczność w zadaniach łączących tekst, wideo i kod, co potwierdza ich wszechstronność.
Podsumowanie: kolejny krok w rozwoju multimodalnego AI
Premiera Gemini 3.1 Pro i Flash-Lite nie jest rewolucją, która od razu zmieni wszystko. To raczej konsekwentne i znaczące udoskonalenie w segmencie wydajnych i skalowalnych modeli multimodalnych. Pokazuje jednak wyraźny kierunek, w którym podąża branża: AI ma być wszechstronnym i dostępnym narzędziem do rozwiązywania realnych problemów. Przeniesienie punktu ciężkości na efektywność kosztową, długi kontekst i głębokie zrozumienie multimodalne świadczy o dojrzewaniu tej technologii.
Dla deweloperów i firm specjalizujących się w integracjach AI pojawienie się ulepszonych, łatwo dostępnych modeli to dobra wiadomość. Otwiera nowe możliwości w projektowaniu aplikacji, które mogą rozumieć świat w sposób bardziej zbliżony do człowieka. Sukces tych modeli będzie mierzony nie tyle wynikami w benchmarkach, ile tym, jak wiele firm i użytkowników uzna, że zaawansowane AI stało się praktycznym i niezawodnym elementem ich pracy.
Projekt Gemini CLI nie zwalnia tempa. Właśnie opublikowano nową stabilną wersję, która wprowadza długo wyczekiwane usprawnienia dla programistów, zwłaszcza fanów Vima. To jednak tylko część obrazu, bo równolegle trwają intensywne prace na kanale nightly, zwiastujące kolejne poważne zmiany w tej otwartoźródłowej konsolowej bramie do modeli Gemini. Wygląda na to, że narzędzie systematycznie przekształca się z ciekawostki w dojrzałe i potężne środowisko pracy.
Stabilny fundament: co nowego w najnowszej wersji
Najnowsza stabilna odsłona skupia się na tym, co najważniejsze: produktywności i elastyczności bezpośrednio w terminalu. Kluczową nowością jest pełna konfigurowalność skrótów klawiaturowych. Programiści mogą teraz definiować własne mapowania klawiszy, a także korzystać z wiązań dosłownych znaków. To ogromny krok w personalizacji, pozwalający dostosować interakcję z AI do indywidualnego, często bardzo ugruntowanego, workflow.
Pod maską działa też usprawniony mechanizm kontekstowy. W dużym skrócie, narzędzia systemu plików ładują kontekst „w ostatniej chwili”. Dzięki temu model otrzymuje najbardziej aktualne i istotne informacje, bez konieczności natychmiastowego przesyłania wszystkich danych. Przekłada się to na lepszą wydajność i celność odpowiedzi.
Ulepszenia dla użytkowników Vima
Jedna z bolączek wcześniejszych wersji – ograniczony tryb Vima – doczekała się poprawek. W Gemini CLI dostępny jest vim mode, który można przełączać i który oferuje podstawową nawigację w trybach NORMAL i INSERT. Pozwala to na bardziej naturalną edycję osobom przyzwyczajonym do skrótów Vima.
Dokumentacja wskazuje na ciągły rozwój tej funkcji, a społeczność zgłasza zapotrzebowanie na dodatkowe, zaawansowane mapowania klawiszy, takie jak operacje na znakach czy pełne wsparcie dla rejestrów. Obecna implementacja stanowi krok w kierunku lepszej integracji z workflow opartym na Vimie.
Tryb Plan: architektoniczny asystent
Do projektu trafił nowy tryb pracy o nazwie Plan Mode. To interesujące podejście do współpracy z AI. Tryb ten, dostępny w ustawieniach jako tryb zatwierdzania (plan approval mode), został zaprojektowany do analizy kodu i planowania zmian.
Jak to działa w praktyce? Po aktywacji Gemini CLI może przeglądać kod, analizować zależności i planować skomplikowane zmiany, które wymagają recenzji i zatwierdzenia przez użytkownika przed wykonaniem. To jak sesja strategiczna, w której AI przedstawia plan działania, a programista decyduje, co i jak chce wdrożyć. Funkcja ta jest niezwykle przydatna do eksploracji nieznanego codebase'u lub planowania refaktoryzacji z zachowaniem pełnej kontroli.
Kanał nightly: gdzie rodzi się przyszłość
Podczas gdy gałąź stabilna oferuje dopracowane funkcje, prawdziwe laboratorium innowacji znajduje się w nightly builds. To tam testowane są najbardziej eksperymentalne pomysły, które często trafiają później do wersji preview, a ostatecznie do stabilnej. Obecny cykl rozwojowy jest wyjątkowo intensywny.
Rozwijane są nowe funkcje, a system telemetrii jest stale ulepszany. Obsługa modeli jest poszerzana, oferując użytkownikom coraz więcej opcji w portfolio.
Usprawnienia dla developerów
Dla developerów pracujących ze skryptami przydatne mogą być różne flagi wyjścia, które pozwalają na bardziej strukturyzowaną interakcję z narzędziem. Praktyczne jest też bezpośrednie osadzanie kontekstu z plików w poleceniach, co eliminuje potrzebę ręcznego kopiowania kodu.
Drobna, ale miła dla oka zmiana: wskaźniki trybów pomagają w orientacji, w jakim stanie znajduje się obecnie interfejs.
Podsumowanie: konsekwentna droga do dojrzałości
Gemini CLI rozwija się w sposób systematyczny. Projekt jasno rozdziela ścieżki: stable dla codziennej, niezawodnej pracy, preview do testowania nowości tuż przed premierą oraz nightly dla śmiałych eksperymentów. Najnowsze zmiany, takie jak konfigurowalne skróty i ulepszenia trybu Vima, to bezpośrednia odpowiedź na potrzeby społeczności.
Jednocześnie prace nad nowymi trybami, takimi jak Plan, pokazują, że twórcy myślą o nowych paradygmatach współpracy z AI. Nie jest to już zwykły wrapper na API, a coraz bogatsze, samodzielne środowisko deweloperskie. Jeśli tempo i kierunek rozwoju się utrzymają, Gemini CLI może stać się nieodzownym narzędziem w terminalu każdego programisty, który chce mieć możliwości Geminiego zawsze pod ręką, bez odrywania się od klawiatury.
Sprawa, która zaczęła się od dociekliwych pytań użytkowników, przerodziła się w pełnowymiarowy skandal w świecie AI do kodowania. Chodzi o Cursor Composer 2, model reklamowany jako autorski, wewnętrzny przełom startupu Cursor. Okazuje się jednak, że pod maską kryje się fine-tuning otwartoźródłowego modelu chińskiej firmy Moonshot AI – Kimi K2.5. Brak przejrzystości, a nie sam fakt użycia open source’u, wywołał burzę.
Społeczność deweloperska czuje się oszukana, a debata wykracza daleko poza pojedynczy produkt. Dotyka fundamentalnych kwestii etyki w AI, transparentności w biznesie opartym na otwartych modelach oraz rosnącej roli chińskich modeli bazowych w globalnym ekosystemie.
Od podejrzeń do twardych dowodów: Linia czasu afery
Wszystko zaczęło się subtelnie, od obserwacji samych użytkowników. Podejrzenia wyszły na jaw w marcu 2026 roku, gdy niektórzy z nich zauważyli, że odpowiedzi generowane przez Composer 2 wykazują zadziwiające podobieństwa do modelu Kimi K2.5. Chodziło o specyficzną strukturę rozumowania, sposób formułowania odpowiedzi i charakterystyczne wzorce znane z narzędzi Moonshot AI. To były jednak tylko przeczucia.
Prawdziwy przełom nastąpił 19 marca 2026 roku za sprawą programisty znanego jako Fynn. To on przeprowadził techniczną analizę zapytań API. Metoda była prosta, ale skuteczna: przekierował ruch z Cursor IDE na lokalny serwer, który pełnił rolę bazowego adresu URL dla OpenAI. To pozwoliło mu zajrzeć za kulisy komunikacji.
Efekt? Ukryty identyfikator modelu w żądaniach Composer 2 bezpośrednio wskazywał na Kimi K2.5 z dodatkowym fine-tuningiem metodą RL (Reinforcement Learning). To nie były domysły, a twardy, powtarzalny dowód. Dwa dni później, 21 marca, na YouTube pojawiły się szczegółowe analizy, które opisały cały proces premiery. Cursor promował wtedy Composer 2 jako własny model, który ma przewyższać nawet wiodące rozwiązania Anthropic, takie jak Claude 3.5 Sonnet, w benchmarkach kodowania, będąc jednocześnie tańszym. O bazie Kimi nie padło ani słowo.
Niepodważalne dowody techniczne: Tokenizer i identyfikatory
Co konkretnie udowodniono? Przede wszystkim zgodność tokenizera. Tokenizer to kluczowy komponent modelu językowego, który dzieli tekst na jednostki. Jak potwierdzili później pracownicy Moonshot AI, tokenizer użyty w Composer 2 jest identyczny z tym, którego używa Kimi K2.5. To jak znalezienie tego samego odcisku palca na dwóch różnych narzędziach – mocny dowód na wspólne pochodzenie.
Dodatkowo analiza API ujawniła ukryty model ID, jednoznacznie powiązany z Kimi. Cursor przedstawiał wyniki benchmarków, wskazując na duże ulepszenia, na przykład +21,5% w Terminal Bench. Jednak gdy przyjrzeć się surowym danym, okazało się, że benchmarki te znacząco różniły się od tych używanych dla Kimi, a ogólny wzrost wydajności był znaczący (np. wynik 61,3 vs. 44,2 w CursorBench). Sugerowało to, że lwia część możliwości modelu pochodziła nie tylko z zaawansowanej, otwartoźródłowej bazy od Moonshot, ale także z własnego treningu Cursor, który pochłonął większość użytej mocy obliczeniowej.
Warto zaznaczyć, że poprzednia wersja, Composer 1 (lub 1.5), opierała się na innym modelu – Qwen. Dopiero Composer 2 w pełni przesiadł się na Kimi, co czyniło brak wzmianki o tym fakcie jeszcze bardziej rażącym.
Reakcje kluczowych graczy: Przyznanie się i partnerstwo
Po ujawnieniu sprawy Cursor nie mógł już milczeć. Lee Robinson, wiceprezes ds. edukacji deweloperów w Cursor, odniósł się do sprawy na platformie X (dawniej Twitter). Jego komentarz był połączeniem przyznania się do błędu i potwierdzenia legalności działań. „Jestem wielkim zwolennikiem open source… To był błąd, że nie wspomnieliśmy o bazie Kimi w naszym wpisie na blogu od samego początku. Naprawimy to przy kolejnym modelu” – napisał. Jednocześnie podkreślił, że zespół Moonshot AI potwierdził, iż użycie było licencjonowane.
To ostatnie to kluczowy punkt. Moonshot AI/Kimi oficjalnie potwierdzili istnienie partnerskiej, autoryzowanej umowy handlowej pomiędzy Cursor a nimi, zawartej za pośrednictwem platformy Fireworks AI. Z prawnego punktu widzenia Cursor prawdopodobnie nie złamał licencji Kimi K2.5, o ile ta dopuszcza komercyjne użycie. Problem leżał jednak w warstwie etycznej i wizerunkowej, a nie prawnej.
Wściekłość społeczności: Dlaczego deweloperzy poczuli się oszukani?
Reakcja społeczności była szybka i pełna oburzenia. Na forach i w komentarzach podkreślano jeden główny zarzut: brak transparentności. Użytkownicy płacili za funkcjonalność w Cursor IDE, wierząc, że finansują rozwój przełomowego, autorskiego modelu startupu. Tymczasem, jak to ujął jeden z komentatorów na YouTube, okazało się, że „Cursor opakowuje open source i odsprzedaje go” w swoim forku VS Code.
Problemem nie było więc użycie otwartego modelu – to powszechna praktyka. Chodziło o stworzenie wrażenia czegoś zupełnie nowego, zbudowanego samodzielnie od zera. To podważa zaufanie. Jeśli deweloperzy nie mogą ufać opisom technologii, na której polegają w codziennej pracy, na czym ma się opierać cały rynek narzędzi AI do kodowania?
Na forum Hacker News pojawiły się nawet spekulacje, czy gigant AI, Anthropic, nie zdecyduje się na zablokowanie Cursor na swoich platformach. Powód? Moonshot AI, twórca Kimi, figuruje na liście firm związanych z tzw. „kampanią ataków destylacyjnych” (distillation attack campaign), obok OpenAI i xAI. Jak dotąd (stan na koniec marca 2026) żaden taki zakaz nie został potwierdzony.
Szersze implikacje: Otwarte źródła, chińskie modele i przyszłość AI
Afera z Cursor Composer 2 to nie tylko historia jednego modelu. To symptom większych trendów i napięć w świecie sztucznej inteligencji.
Po pierwsze, jasno pokazuje, że społeczność deweloperska domaga się nowych standardów transparentności. Wskazana została paląca potrzeba publikowania jawnych „kart modelu” (model cards) i dokumentacji, które wprost wymieniają modele bazowe, nawet jeśli mowa tylko o fine-tuningu. Chodzi o uczciwość intelektualną, która pozwala użytkownikom dokonywać świadomych wyborów.
Po drugie, sprawa rzuca światło na rosnącą dominację chińskich modeli bazowych, takich jak Kimi, Qwen czy DeepSeek, w globalnym ekosystemie open source. Są one często darmowe, potężne i łatwo dostępne. Firma z Doliny Krzemowej, taka jak Cursor, może na nich budować swoją wartość. To budzi mieszane uczucia w kontekście geopolitycznym i zmusza do pytań o długoterminową niezależność technologiczną Zachodu. Niektórzy politycy już ostrzegają przed chińską dominacją w obszarze open-source AI.
Po trzecie, kwestionuje to model biznesowy małych, zwinnych zespołów, które budują narzędzia na cudzych, otwartych fundamentach. Jeśli ich główną wartością jest tylko opakowanie i fine-tuning, jak mogą konkurować, gdy dostawcy modeli bazowych zaczną oferować podobne usługi bezpośrednio? Rynek agentów kodujących rozwija się błyskawicznie, a zaufanie jest tu kluczowym aktywem, który łatwo stracić.
Podsumowanie: Lekcja na przyszłość
Afera Cursor Composer 2 wciąż się rozwija, ale już dostarczyła ważnej lekcji dla całej branży. Legalne użycie otwartoźródłowego modelu to za mało. W erze, w której fundamentem innowacji jest współdzielona praca tysięcy badaczy i inżynierów, przejrzystość staje się nową walutą zaufania.
Cursor przyznał się do przeoczenia w kwestii atrybucji, ale nie wystosował pełnych przeprosin ani nie zrewidował szczegółowo swojej dokumentacji. To może być dla nich kosztowny błąd wizerunkowy. Dla deweloperów natomiast jest to wyraźny sygnał, by podchodzić do marketingowych deklaracji o „własnych”, „przełomowych” modelach z dużą dozą zdrowego sceptycyzmu i domagać się technicznych szczegółów.
Ostatecznie ta historia nie kończy się na Kimi czy Cursorze. To rozdział w szerszej opowieści o tym, jak budujemy etyczny i zrównoważony ekosystem AI, w którym współpraca i otwartość idą w parze z uczciwością wobec tych, którzy z tych technologii korzystają.
Anthropic, twórca zaawansowanego modelu AI Claude, znacząco poszerza zakres działania swojego asystenta poza przeglądarkę. Firma właśnie udostępniła w pełni interaktywne aplikacje na iOS i Androida, które zamieniają zwykły czat w dynamiczne środowisko pracy z wizualizacjami i narzędziami. Równolegle, z myślą o programistach i specjalistach DevOps, rozbudowano funkcje Claude Code o natywny dostęp do terminala i kontrolę komputera, oferując głęboką integrację ze środowiskiem lokalnym. To już nie tylko rozmowy z AI, ale platformy do realnego działania.
Mobilny Claude z interfejsem dotykowym
Wczesną wiosną 2026 roku użytkownicy subskrypcji Pro, Max, Team oraz Enterprise mogą pobrać odświeżone aplikacje mobilne Claude. Ich kluczową nowością jest możliwość uruchamiania w obrębie samej konwersacji dedykowanych, interaktywnych aplikacji. Oznacza to koniec z przeglądaniem statycznych zrzutów ekranu czy opisów.
Teraz, gdy poprosisz Claude’a o analizę danych, w oknie czatu może wyrenderować się interaktywny wykres generowany w czasie rzeczywistym. Możesz poprosić o diagram architektury systemu i otrzymać go w formie przejrzystego rysunku, który od razu można udostępnić. Jednak największą zmianą jest bezpośredni dostęp do narzędzi pracy.
Jak to działa w praktyce? W aplikacji mobilnej otwierasz katalog integracji (dostępny pod adresem claude.ai/directory) i aktywujesz wybrane narzędzia. Od tego momentu w trakcie rozmowy z Claude’em możesz: ** wysłać wiadomość na kanale Slack bez przełączania aplikacji;** stworzyć lub edytować projekt graficzny w Canvie; ** dokonać przeglądu lub nanieść drobne poprawki w prototypie w Figmie;** przejrzeć i pobrać pliki z chmury Box.
„Analiza danych, projektowanie treści i zarządzanie projektami – wszystko to działa lepiej z dedykowanym interfejsem wizualnym. W połączeniu z inteligencją Claude’a można pracować i wprowadzać iteracje szybciej, niż oferowałoby każde z tych narzędzi osobno” – wskazuje zespół Anthropic.
Dla web developerów czy osób pracujących z AI takie „szkicowanie” diagramów przepływu danych podczas burzy mózgów nad vibe codingiem lub szybki podgląd prototypu UI w trakcie dyskusji o konfiguracji hostingu staje się natychmiastowe. Praca koncepcyjna i wykonawcza zlewa się w jeden płynny proces na telefonie.
Produktywność bez granic: od telefonu do komputera
Aplikacje mobilne nie są odizolowaną wyspą. Ich prawdziwa moc ujawnia się w połączeniu z Claude’em działającym na komputerze stacjonarnym lub laptopie. Funkcje zdalnego sterowania pozwalają na automatyzację zadań.
Wyobraź sobie taki scenariusz: jesteś w trasie, a na telefonie dostajesz informację, że potrzebna jest aktualna wersja prezentacji w PDF. W aplikacji mobilnej zlecasz Claude’owi zadanie: „Wyeksportuj najnowszą wersję pliku prezentacja_pitch.deck z pulpitu do PDF i dołącz go jako załącznik do zaproszenia na spotkanie w kalendarzu na jutro na 10:00”.
Claude, korzystając z sesji Claude Code uruchomionej na laptopie w domu lub biurze (który musi być włączony), wykonuje tę sekwencję czynności: odnajduje plik, uruchamia odpowiednią aplikację, eksportuje go do PDF, otwiera kalendarz, lokalizuje spotkanie i załącza plik. Ty na telefonie otrzymujesz tylko potwierdzenie wykonania.
Ta automatyzacja sprawdza się w powtarzalnych zadaniach: skanowaniu skrzynki mailowej pod kątem pilnych wiadomości, generowaniu cotygodniowych raportów, przetwarzaniu wsadowym zdjęć czy automatycznym przechwytywaniu i katalogowaniu zrzutów ekranu. Dla zespołów DevOps oznacza to możliwość zdalnego, głosowego lub tekstowego uruchamiania skryptów, restartowania usług czy monitorowania logów – bez konieczności otwierania laptopa i nawiązywania połączenia SSH. Zadanie wysyłasz z telefonu, a Claude wykonuje je na zdalnej maszynie.
Nowa era dla developerów: Claude Code, terminal i zdalna kontrola
Jeśli aplikacje mobilne służą głównie do interakcji i zlecania pracy, to rozszerzenia Claude Code dają narzędzia do jej faktycznego wykonania. Rozwój tej funkcji idzie w stronę pełnej integracji z systemem operacyjnym i środowiskiem programistycznym.
Niedawno dodana funkcja computer use (w wersji preview od 23 marca) pozwala Claude’owi nie tylko pisać kod, ale również nawigować po interfejsie komputera. Model może klikać, przeciągać elementy, otwierać aplikacje, uruchamiać narzędzia deweloperskie czy przeglądać strony. Nie wymaga to żadnej specjalnej konfiguracji. To fundament pod zdalną automatyzację – skoro Claude potrafi samodzielnie korzystać z komputera, może też wykonać zdalnie zlecone mu zadanie.
Dla programistów kluczowy jest jednak natywny dostęp do terminala. Claude Code działa jako agent terminalowy, który odczytuje rzeczywiste pliki projektu z lokalnej maszyny, z gwarancją, że dane nie opuszczają komputera poza wywołaniami API do Anthropic. W praktyce daje to pełny dostęp do wiersza poleceń na Twoim komputerze.
Możesz zlecić Claude’owi kompilację projektu, uruchomienie serwera deweloperskiego, przeanalizowanie logów za pomocą grep, a nawet zarządzanie kontenerami Docker. Sesja działa lokalnie, więc masz dostęp do tych samych plików, zmiennych środowiskowych i narzędzi.
Oczywiście istnieją pewne ograniczenia. Interfejs terminala na małym ekranie nie jest jeszcze w pełni zoptymalizowany pod kątem UX, a sama sesja zdalna jest pojedyncza i wymaga, aby komputer docelowy był włączony. W przypadku niestabilności połączenia sesja może się rozłączyć po około 10 minutach. Niemniej dla pilnych zadań operacyjnych to potężne udogodnienie.
Warto wiedzieć, że cała ta infrastruktura opiera się na otwartym standardzie Model Context Protocol (MCP), który Anthropic udostępniło w 2024 roku i który zyskał również wsparcie ze strony OpenAI. MCP standaryzuje sposób, w jaki modele AI komunikują się z zewnętrznymi narzędziami i danymi, co otwiera drogę do dalszej, szerszej integracji.
Podsumowanie: AI jako system operacyjny do pracy
Nowości z wiosny 2026 – najpierw computer use (23.03), potem interaktywne aplikacje mobilne – układają się w spójną wizję. Claude przestaje być chatbotem, a staje się warstwą operacyjną pośredniczącą między intencją użytkownika a wykonaniem zadania w dowolnym podłączonym narzędziu lub systemie.
Dla użytkownika mobilnego oznacza to skrócenie drogi od pomysłu do wizualizacji czy komunikacji. Dla dewelopera i specjalisty DevOps – możliwość zarządzania złożonymi technicznymi workflow za pomocą prostego polecenia głosowego lub tekstowego, niezależnie od miejsca pobytu. Integracja z najnowszymi modelami Claude dodatkowo napędza tę wizję, pozwalając generować działające aplikacje czy skrypty bezpośrednio z opisu w języku naturalnym, również na telefonie.
Anthropic konsekwentnie buduje nie tyle kolejnego asystenta AI, co wieloplatformowy system wykonawczy. Nie chodzi już tylko o dostarczanie informacji, ale o realne, interaktywne i zautomatyzowane działanie we wszelkich cyfrowych środowiskach, w których pracujemy. To krok w stronę przyszłości, w której bariera między poleceniem a rezultatem staje się niemal niezauważalna.
Wyciek prawie 3000 wewnętrznych dokumentów z systemów Anthropic wstrząsnął światem AI. Nie chodziło jednak o kolejną drobną usterkę. W publicznym cache'u znalazły się plany dotyczące czegoś, co może zmienić układ sił: nowego, najpotężniejszego modelu o kryptonimie Capybara i roboczej nazwie Claude Mythos. Plotki, które od miesięcy krążyły w społeczności, nagle zyskały twarde potwierdzenie. I choć to tylko szkic, a nie oficjalna premiera, ujawnione szczegóły pozwalają mówić o potencjalnym skoku generacyjnym.
Sprawę ujawnił błąd konfiguracji w wewnętrznym systemie zarządzania treścią firmy, co zostało przeanalizowane przez zewnętrzne redakcje. To właśnie tam, między wierszami dokumentów, ukryta była informacja o czymś większym niż Claude Opus.
Nowa hierarchia: Mythos góruje nad Opus
Anthropic od dawna buduje swoją ofertę wokół trójstopniowej drabiny modeli. Na szczycie stał dotąd Claude Opus, niżej Sonnet, a na dole Haiku. To przejrzysty podział, który klienci już poznali i polubili. Wyciek ujawnił jednak, że firma szykuje czwarty, najwyższy poziom. I nie będzie to drobna aktualizacja.
Claude Mythos, wewnętrznie nazywany Capybara (od największego gryzonia na świecie), ma zająć pozycję wyraźnie powyżej obecnego topowego modelu Opus. Przeanalizowane dokumenty nie pozostawiają wątpliwości: model „uzyskuje dramatycznie wyższe wyniki”. To sformułowanie, które pada w kontekście kluczowych benchmarków. Szczególnie mocno podkreślane są trzy dziedziny: kodowanie, rozumowanie akademickie oraz – co budzi największe emocje – cyberbezpieczeństwo.
Co to oznacza w praktyce? Jeśli wierzyć szkicom, Capybara może oferować wsparcie programistyczne na poziomie nieosiągalnym dla obecnych asystentów. Reasoning, czyli zdolność do logicznego wnioskowania w skomplikowanych problemach akademickich, również ma wejść na nowy poziom. Ale to trzecia umiejętność rzuca najdłuższy cień.
Cyberbezpieczeństwo: obosieczny miecz Capybary
To właśnie tutaj wyciek staje się najbardziej niepokojący. Jeden z dokumentów zawiera zdanie, które zapada w pamięć: model jest opisywany jako znacznie bardziej zaawansowany pod względem możliwości cybernetycznych. W świecie, który dopiero uczy się żyć z zagrożeniami ze strony AI, taka deklaracja brzmi jak ostrzeżenie.
Anthropic zdaje się być tego w pełni świadomy. Firma w ujawnionych materiałach podkreśla potrzebę działania „z dodatkową ostrożnością”. Chce dokładnie zrozumieć związane z tym ryzyka, szczególnie w obszarze cybersecurity. Dlaczego? Aby pomóc obrońcom – specjalistom od bezpieczeństwa IT – przygotować się na potencjalną nową falę ataków napędzanych przez sztuczną inteligencję tej klasy.
To niezwykle odpowiedzialne, ale i strategiczne podejście. Zamiast wypuszczać potencjalnie niebezpieczne narzędzie na otwarty rynek, Anthropic planuje, według dokumentów, udostępnić je najpierw wąskiej grupie ekspertów od cyberbezpieczeństwa. Ma to na celu wzmocnienie ich pozycji w wyścigu zbrojeń z przestępcami, którzy z pewnością też będą chcieli wykorzystać podobną technologię.
Status projektu: testy tak, publiczny release nie
Co teraz z samym modelem? Według wyciekłego szkicu wpisu na blogu, model o nazwach Claude Mythos/Capybara istnieje. Anthropic publicznie potwierdził testy nowego, przełomowego modelu z klientami w ramach early access, ale nie użył konkretnych nazw „Mythos” czy „Capybara”. Z dokumentów wynika, że model ukończył fazę treningową, co sugeruje zaawansowany etap rozwoju. Jednak kluczowa informacja brzmi: firma podkreśla niezwykle ostrożne podejście i brak sztywnego harmonogramu publicznej premiery.
To ważne rozróżnienie. Model nie jest gotowym produktem czekającym na półce. Jest raczej potężnym narzędziem badawczym i strategicznym, które zostanie najpierw użyte w kontrolowanym środowisku. Dostęp, jak wynika z przecieków, ma być ograniczony początkowo do zaufanych organizacji i specjalistów od cyberbezpieczeństwa. To środowisko, w którym ryzykiem można lepiej zarządzać, a korzyści – dokładnie zmierzyć.
Taka strategia przypomina nieco podejście do zaawansowanych technologii w sektorze obronnym. Najpierw trafiają one do jednostek specjalnych, zanim – o ile w ogóle – staną się powszechnie dostępne. Anthropic zdaje się traktować zaawansowane zdolności cybernetyczne AI z podobną powagą.
Co to znaczy dla rynku i przyszłości AI?
Wyciek o Claude Mythos, nawet będący jedynie szkicem, jasno pokazuje kierunek, w którym zmierza wyścig gigantów AI. Nie chodzi już tylko o to, kto napisze lepszy wiersz lub podsumuje artykuł. Kluczowa walka toczy się o twarde, praktyczne umiejętności: tworzenie kodu, rozwiązywanie złożonych problemów naukowych i operacje w cyberprzestrzeni.
Fakt, że Anthropic priorytetowo traktuje cyberbezpieczeństwo, jest znaczący. Pokazuje, że liderzy branży zaczynają postrzegać potęgę swoich modeli nie tylko przez pryzmat korzyści, ale i nieodłącznych zagrożeń. Responsible AI przestaje być pustym hasłem z broszury marketingowej, a staje się centralnym elementem strategii wdrażania.
Pojawienie się nowego poziomu „Mythos” powyżej „Opus” stawia też pytanie o przyszłość oferty Anthropic. Czy to jednorazowy, superzaawansowany projekt do wąskich zastosowań? Czy może zapowiedź nowej, stałej linii produktów, która na zawsze podniesie poprzeczkę? Odpowiedź na to pytanie będzie kształtować nie tylko przyszłość samej firmy, ale i oczekiwania wszystkich użytkowników zaawansowanej sztucznej inteligencji.
Podsumowanie: między potencjałem a ostrożnością
Historia Claude'a Mythos to na razie opowieść złożona z przecieków, potwierdzonych testów i daleko idącej ostrożności. Capybara, jak na największego gryzonia przystało, ma być potężna, ale jej siła budzi respekt nawet u twórców. Dramatycznie lepsze kodowanie i reasoning to obietnica kolejnej rewolucji w produktywności. Jednak to bezprecedensowe zdolności w dziedzinie cyberbezpieczeństwa czynią z tego modelu obiekt zarówno ogromnych nadziei, jak i głębokich obaw.
Strategia Anthropic – najpierw testy z obrońcami, potem ewentualnie szersze wdrożenie – wydaje się rozsądnym, choć niepozbawionym wyzwań podejściem do technologii o tak dużej sile rażenia. Wyciek, choć niezamierzony, postawił firmę i całą branżę przed ważną publiczną dyskusją na temat granic i odpowiedzialności. Zanim Capybara pokaże pełnię swoich możliwości, świat ma szansę przygotować się na jej nadejście. A to może być najcenniejszym efektem całego tego zamieszania.
Najnowsza aktualizacja Gemini CLI, oznaczona numerem wersji v0.36.0-nightly.20260318.e2658ccda, to duży krok naprzód w rozwoju terminalowego narzędzia od Google. Skupia się ona na dwóch kluczowych filarach: rozszerzeniu zdolności agentowych oraz znaczącym wzmocnieniu architektury bezpieczeństwa. Dla deweloperów oznacza to bardziej niezawodne, kontrolowane i wydajne środowisko dla workflowów asystowanych przez AI, takich jak vibe coding, migracje legacy code czy automatyzacja DevOps.
Przebudowa rdzenia agentów: AgentLoopContext
Kluczową zmianą techniczną tej wersji jest pełna migracja pakietu `core` na `AgentLoopContext`. Może to brzmieć jak szczegół implementacyjny, ale w praktyce ma fundamentalne znaczenie dla stabilności i rozszerzalności całego systemu. AgentLoopContext stanowi ujednolicony kontekst wykonania dla pętli agenta, dzięki czemu zarządzanie stanem, narzędziami i pamięcią staje się bardziej przewidywalne i mniej podatne na błędy.
Bezpośrednio z tym wiążą się zmiany w architekturze. Sub-agenci to mniejsze, wyspecjalizowane jednostki AI, które mogą być uruchamiane równolegle lub sekwencyjnie w celu wykonania konkretnych podzadań. Nowa struktura kontekstu ułatwia zarządzanie ich stanem i wykonaniem.
Architektura bezpieczeństwa również została wzmocniona. Jeśli agent postanowi wykonać polecenie shellowe lub skrypt, operacje te są lepiej kontrolowane, co minimalizuje ryzyko przypadkowego uszkodzenia systemu hosta. To przejście w stronę filozofii „shift-left security” w workflowach deweloperskich – zabezpieczenia są wbudowane w proces od samego początku, a nie dodawane na końcu.
Rozszerzona konfiguracja i kontrola
Ta wersja wprowadza zaawansowane możliwości konfiguracji, pozwalające na głęboką personalizację zachowania agenta bez potrzeby modyfikacji kodu źródłowego CLI. Dają one programistom pełną kontrolę nad cyklem życia sesji i wykonywanych operacji.
Umożliwia to precyzyjne dostosowywanie zachowania agenta. Można na przykład automatycznie wczytywać historię Gita danego projektu na początku sesji, aby agent od razu miał kontekst ostatnich zmian, lub dodawać dodatkową walidację przed wykonaniem planowanych operacji.
Bezpieczeństwo: domeny i polityki
Oprócz ulepszeń architektonicznych ta wersja wprowadza ważne ustawienia bezpieczeństwa. Pojawia się możliwość definiowania ograniczeń domenowych dla agenta przeglądarkowego (allowed domain restrictions). Można dzięki temu zezwolić agentowi na automatyzację działań tylko w wybranych, zaufanych domenach, co ogranicza ryzyko przypadkowej interakcji ze szkodliwymi stronami.
Dla zespołów lub użytkowników wymagających maksymalnej kontroli dostępne są opcje pozwalające na zarządzanie systemem zatwierdzania operacji. To cenna funkcja w środowiskach produkcyjnych lub przy pracy z wrażliwym kodem.
Mechanizmy zarządzania zadaniami (todos) i trackerami projektu zostały udoskonalone, co wprowadza kolejną warstwę kontroli nad planowaniem działań. Wynika to częściowo z szeregu zmian w module tracker.
Lepszy kontekst, MCP i obsługa języków CJK
Wydajność agentów AI jest wprost proporcjonalna do jakości i trafności kontekstu, który otrzymują. Wersja v0.36.0-nightly.20260318.e2658ccda kontynuuje usprawnienia w tym obszarze. Wprowadzono hierarchiczne ładowanie kontekstu z plików GEMINI.md. System sprawdza plik globalny (np. ~/.gemini/global-context.md), potem projektowy, a na końcu specyficzny dla podfolderu – przy czym bardziej szczegółowy kontekst nadpisuje ogólny. Zapewnia to spójną, trwałą „pamięć projektu” bez konieczności powtarzania tych samych instrukcji w promptach.
Integracja z serwerami MCP (Model Context Protocol) pozostaje kluczowym elementem ekosystemu. Pozwala ona podłączać zewnętrzne serwery, które udostępniają agentowi niestandardowe narzędzia – np. do wykonywania zapytań do prywatnej bazy danych, integracji z Figmą czy zarządzania infrastrukturą chmurową. To wydajny sposób na rozszerzenie możliwości agenta bez „zanieczyszczania” jego głównego promptu.
Warto też odnotować poprawę obsługi wprowadzania znaków CJK (chińskich, japońskich, koreańskich) oraz pełną obsługę skalarnych wartości Unicode w protokołach terminala. To ważne ułatwienie dla międzynarodowych zespołów deweloperskich.
Optymalizacje wydajnościowe i poprawki błędów
Pod maską przeprowadzono szereg optymalizacji, które przekładają się na płynniejsze działanie. Zależności w TrackerService zostały zoptymalizowane, co przyspiesza sprawdzanie stanu zadań. Interfejs trackera został dopracowany – poprawiono sortowanie i formatowanie, co zwiększa czytelność.
Wprowadzono również model Topic-Action-Summary dla promptów, którego celem jest redukcja nadmiernej gadatliwości (verbosity) modeli, co przekłada się na oszczędność tokenów i bardziej zwartą komunikację.
Lista poprawek błędów jest długa i obejmuje m.in. naprawę ręcznego usuwania historii sub-agentów, deduplikację pamięci projektu przy włączonym JIT context, lepsze zarządzanie konfliktami komend dla skills oraz obsługę sesji w Git worktrees dla izolowanej pracy równoległej.
Podsumowanie: dojrzałość ekosystemu agentów AI
Wydanie Gemini CLI v0.36.0-nightly.20260318.e2658ccda nie wprowadza jednej, głośnej funkcji, lecz konsekwentnie wzmacnia fundamenty pod zaawansowane, produkcyjne użycie agentów AI w terminalu. Migracja na AgentLoopContext, uszczelnienie architektury bezpieczeństwa oraz rozbudowane możliwości konfiguracji tworzą ramy, w których kontrola idzie w parze z automatyzacją.
Dla deweloperów pracujących nad modernizacją legacy code, automatyzacją DevOps czy po prostu stosujących vibe coding, zmiany te oznaczają mniej niespodzianek, większą przewidywalność i zaufanie do narzędzia. Ta wersja Gemini CLI dostarcza zarówno mocniejszy „silnik”, jak i bardziej zaawansowane systemy kontroli, ułatwiając efektywną pracę.
Wydanie pakietu @openai/codex miało być krokiem naprzód, dając użytkownikom prosty interfejs do uruchamiania modeli OpenAI w terminalu. Szybko okazało się jednak, że to podstawowe narzędzie, służące głównie do uwierzytelniania i obsługi interfejsu tekstowego (TUI), nie spełnia oczekiwań osób szukających zaawansowanej automatyzacji z wykorzystaniem agentów AI. Brak funkcji kontroli uprawnień, zarządzania zadaniami czy integracji z pipeline'ami CI/CD sprawia, że narzędzie nie przystaje do potrzeb programistów.
Problemy zgłaszane przez społeczność pokazują, że narzędzie ogranicza się do podstawowych operacji, takich jak codex login czy codex "fix the failing tests". To rozmija się z oczekiwaniami, zwłaszcza w kontekście vibe coding czy automatyzacji zadań DevOps, gdzie kluczowa jest płynna iteracja i zaawansowana kontrola.
Jak wygląda rzeczywistość? Ograniczony zakres
Wyobraź sobie, że chcesz, aby agent AI przeanalizował strukturę projektu, znalazł pliki, podmienił w nich tekst, a potem sprawdził efekt. W normalnych warunkach to seria szybkich operacji, które można by zautomatyzować. W przypadku podstawowego CLI @openai/codex taki scenariusz jest niemożliwy. Narzędzie nie oferuje mechanizmów zatwierdzania poszczególnych komend, zarządzania sesjami ani tworzenia złożonych workflowów.
Użytkownicy wskazują, że próby użycia go jako pełnoprawnego systemu agentowego są skazane na niepowodzenie. W pliku konfiguracyjnym brakuje opcji typu autoApprove=true, ponieważ system zatwierdzeń w ogóle nie istnieje. Nie ma też prostego obejścia (workaroundu), które pozwoliłoby przekształcić go w zaawansowane narzędzie. Jedynym rozwiązaniem pozostaje poszukiwanie innych, bardziej rozbudowanych platform lub frameworków.
Sam interfejs jest prosty i przejrzysty, ale właśnie przez tę prostotę nie obsługuje złożonych sekwencji komend czy operacji łańcuchowych (chaining). Stwarza to wyraźną lukę między oczekiwaniami a rzeczywistymi możliwościami narzędzia.
Wpływ na oczekiwania dotyczące kontroli nad agentami
Idea "pełnej kontroli nad agentami", którą niektórzy mogli wiązać z nazwą "Codex", nie znajduje potwierdzenia w tym konkretnym narzędziu CLI. Zamiast inteligentnego zarządzania uprawnieniami czy zautomatyzowanych łańcuchów zadań, użytkownik otrzymuje podstawowe polecenia do uruchomienia modelu w trybie tekstowym.
Weźmy pod uwagę typowy scenariusz dla web developmentu czy DevOps: agent ma zainstalować zależności, przebudować projekt i uruchomić testy. Dojrzały, zaawansowany system agentowy mógłby to wykonać, jednak CLI @openai/codex nie zostało zaprojektowane do takich zadań. Praca z podagentami czy delegowanie zadań w piaskownicy (sandbox) jest przez to niemożliwe.
Co ciekawe, rozwój OpenAI zmierza w innym kierunku. Oryginalny model Codex został wycofany w 2023 roku i zastąpiony przez modele z rodziny GPT (np. gpt-4). Obecne oficjalne narzędzia i API wykorzystują te nowsze modele, a nazwa "Codex" w kontekście CLI odnosi się do podstawowego pakietu pomocniczego, a nie do zaawansowanej platformy agentowej.
Czy ograniczenia zahamują adopcję? Zagrożenie dla produktywności
Dla społeczności skupionej wokół sztucznej inteligencji w programowaniu wydajność i płynność działania są kluczowe. Zaawansowane agenty AI mają przyspieszać pracę, tymczasem podstawowe CLI, służące głównie do uwierzytelniania i obsługi prostych promptów, nie spełnia tych założeń. Jest to szczególnie odczuwalne w zadaniach iteracyjnych, które stanowią sedno vibe coding – szybkiego prototypowania i eksperymentowania z kodem przy wsparciu AI.
Ograniczenia te stanowią poważną barierę dla deweloperów szukających stabilnego środowiska do integracji agentów AI w swoich workflowach czy pipeline'ach CI/CD. Użytkownicy mogą po prostu zrezygnować z narzędzia, które nie oferuje potrzebnych im funkcji. Oczekiwania wobec marki "Codex" były wysokie, a rzeczywistość okazała się skromniejsza.
Funkcjonalności takie jak zaawansowane systemy zatwierdzania (np. "guardian review"), obecne w innych platformach, są tu nieobecne. Użytkownicy zostali z bardzo prostym narzędziem, które nie pełni roli zaawansowanego systemu agentowego.
Znaczenie zrozumienia zakresu narzędzia
Problem jest na tyle powszechny, że w społeczności może panować zamieszanie co do możliwości różnych rozwiązań. Z jednej strony to naturalne – deweloperzy szukają efektywnych metod pracy. Z drugiej strony prowadzi to do rozczarowania, gdy narzędzie nie spełnia wyobrażeń opartych na nazwie lub niepełnych informacjach.
Dla użytkowników CLI, rozszerzeń do VS Code czy narzędzi TUI (Text-based User Interface), którzy napotkali te ograniczenia, jest to kwestia blokująca realizację projektów. Przejrzysta dokumentacja i rzetelne informacje są niezbędne, aby uniknąć nieporozumień co do zakresu funkcjonalności.
Oficjalne wsparcie kieruje użytkowników do dokumentacji dostępnych modeli i API, co jest w tym przypadku właściwym kierunkiem. Brak prostej metody rozszerzenia podstawowego CLI potęguje potrzebę wyraźnego rozgraniczenia między poszczególnymi produktami i ich możliwościami.
Podsumowanie sytuacji
Rzeczywisty zakres pakietu @openai/codex to klasyczny przykład tego, jak nazwa i skojarzenia mogą budować oczekiwania wykraczające poza możliwości prostego narzędzia. Zamiast dawać użytkownikom pełną agentowość, oferuje on jedynie podstawowy interfejs do uruchamiania modeli w terminalu.
Rozbieżność ta uderza w obietnice automatyzacji i wsparcia AI w programowaniu. Pokazuje to, jak ważne jest precyzyjne definiowanie możliwości narzędzi deweloperskich. Dla społeczności to cenna lekcja, by zawsze weryfikować oficjalną dokumentację i listę funkcji przed integracją nowego rozwiązania.
Szybki rozwój modeli GPT i ich integracja w różnych środowiskach to pozytywny sygnał, ale jednocześnie wyzwanie w zakresie klarownej komunikacji. Społeczność programistów jest wyrozumiała dla ograniczeń technicznych, ale ma mało cierpliwości dla niejasności. Od tego, jak precyzyjnie będą prezentowane możliwości produktów, może zależeć zaufanie użytkowników do dalszego rozwoju ekosystemu.