Dla programistów pracujących z AI w trybie tekstowym (TUI) precyzja i niezawodność są kluczowe. Najnowsza aktualizacja OpenCode, wersja 1.3.6, koncentruje się na dwóch aspektach: usprawnieniu wyszukiwania w interfejsie oraz naprawie krytycznego błędu w śledzeniu zużycia zasobów. To zestaw poprawek, które choć technicznie niewielkie, mają realny wpływ na codzienny komfort pracy.
Wydanie z 29 marca 2026 roku przynosi konkretne rozwiązania dla użytkowników ceniących szybkość i dokładność w interakcji z narzędziami sztucznej inteligencji, takimi jak Claude czy modele z Amazon Bedrock. W erze vibe coding, gdzie płynność pracy bez zbędnych przeszkód ma ogromne znaczenie, takie aktualizacje są na wagę złota.
Usprawnione wyszukiwanie w oknie wariantów (TUI)
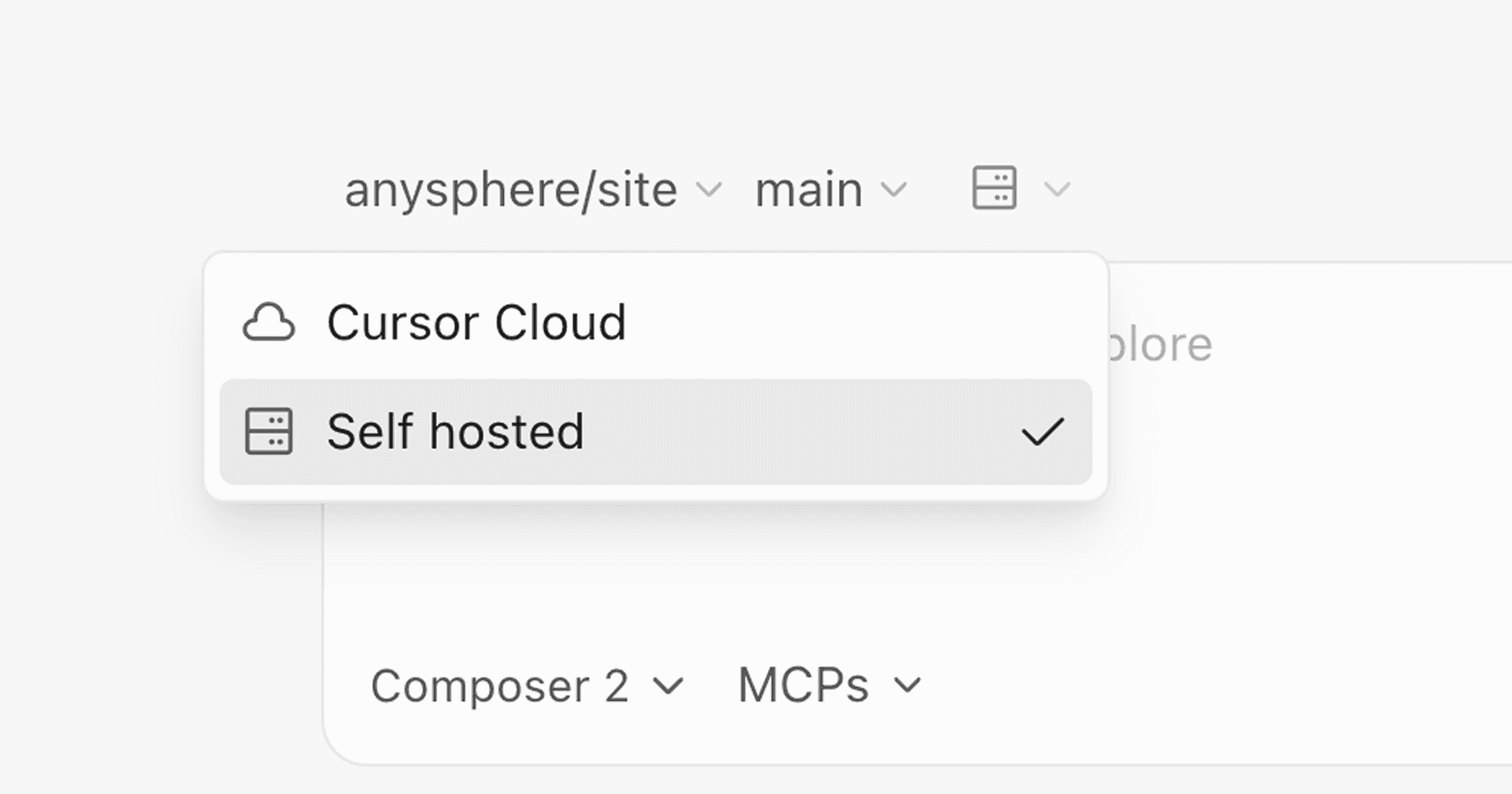
Jedną z najbardziej odczuwalnych zmian dla użytkowników interfejsu tekstowego jest poprawka wprowadzona w ramach pull requestu #19917. Dotyczyła ona działania wyszukiwania w oknie dialogowym wyboru wariantów modeli. Wcześniej zdarzało się, że wpisywanie tekstu nie filtrowało prawidłowo dostępnej listy, co zmuszało użytkownika do uciążliwego przewijania.
Teraz mechanizm ten działa prawidłowo – wpisane znaki na bieżąco zawężają wyniki. To pozornie drobne usprawnienie w praktyce znacząco przyspiesza kluczowy moment wyboru odpowiedniego modelu czy konfiguracji agenta. Dodatkowo twórcy wprowadzili kolory z motywu graficznego dla tekstów zastępczych (placeholder) w polach tekstowych oraz udoskonalili zachowanie samego modala, czyniąc go mniej inwazyjnym.
W kontekście szerszych prac nad TUI w tym cyklu wydawniczym warto wspomnieć też o przywróceniu domyślnej obsługi protokołu klawiatury Kitty w terminalach na Windowsie oraz opcji wyłączenia przechwytywania myszy przez zmienną środowiskową OPENCODE_DISABLE_MOUSE. Pokazuje to dbałość o różnorodne środowiska pracy deweloperów.
Koniec z podwójnym liczeniem tokenów dla Anthropic i Bedrock
Drugim filarem tego wydania jest naprawa istotnego błędu w rdzeniu aplikacji (PR #19758). Chodziło o problem z podwójnym naliczaniem tokenów dla dostawców Anthropic i Amazon Bedrock. Błąd ten prowadził do zawyżonych metryk zużycia w statystykach sesji, co mogło skutkować błędnym szacowaniem kosztów lub limitów użycia, zwłaszcza w środowiskach korporacyjnych.
Poprawka gwarantuje, że tokeny są liczone dokładnie raz. Dla zespołów ściśle monitorujących budżet związany z korzystaniem z płatnych modeli AI jest to zmiana o fundamentalnym znaczeniu. Precyzyjne śledzenie zużycia to podstawa w DevOps i zarządzaniu zasobami chmurowymi, gdzie każda jednostka ma swoją cenę.
Oprócz tej kluczowej poprawki, w szerszym kontekście wersji 1.3.6, zespół OpenCode kontynuował gruntowną refaktoryzację wewnętrznych usług (takich jak Config czy Session) w kierunku architektury opartej na bibliotece Effect, co ma poprawić stabilność i przewidywalność działania całego systemu.
Dlaczego te poprawki mają znaczenie?
Wydanie OpenCode v1.3.6 to doskonały przykład tego, jak dojrzałe projekty open source dbają o szczegóły. Nie znajdziemy tu rewolucyjnych funkcji, lecz konkretne, wymierne ulepszenia, które bezpośrednio przekładają się na jakość codziennej pracy.
Usprawnienie wyszukiwania w TUI minimalizuje frustrację i skraca czas interakcji z narzędziem, pozwalając programiście skupić się na tym, co najważniejsze – na kodzie. Z kolei naprawa licznika tokenów przywraca zaufanie do danych diagnostycznych, niezbędnych do efektywnego zarządzania zasobami AI. W połączeniu z innymi niedawnymi nowościami, takimi jak wieloetapowe uwierzytelnianie dla GitHub Copilot Enterprise czy interaktywny proces aktualizacji, OpenCode konsekwentnie buduje pozycję solidnego i przewidywalnego środowiska do AI-assisted coding. W świecie szybko rozwijających się modeli i narzędzi taka stabilność fundamentów jest często tym, czego deweloperzy potrzebują najbardziej.